|
Gateway to the Early Modern World |
Gateway |
Research |
|
|
A Description of the Notes Form
To view a description of each field in the screen shot below, go to the table below the form.
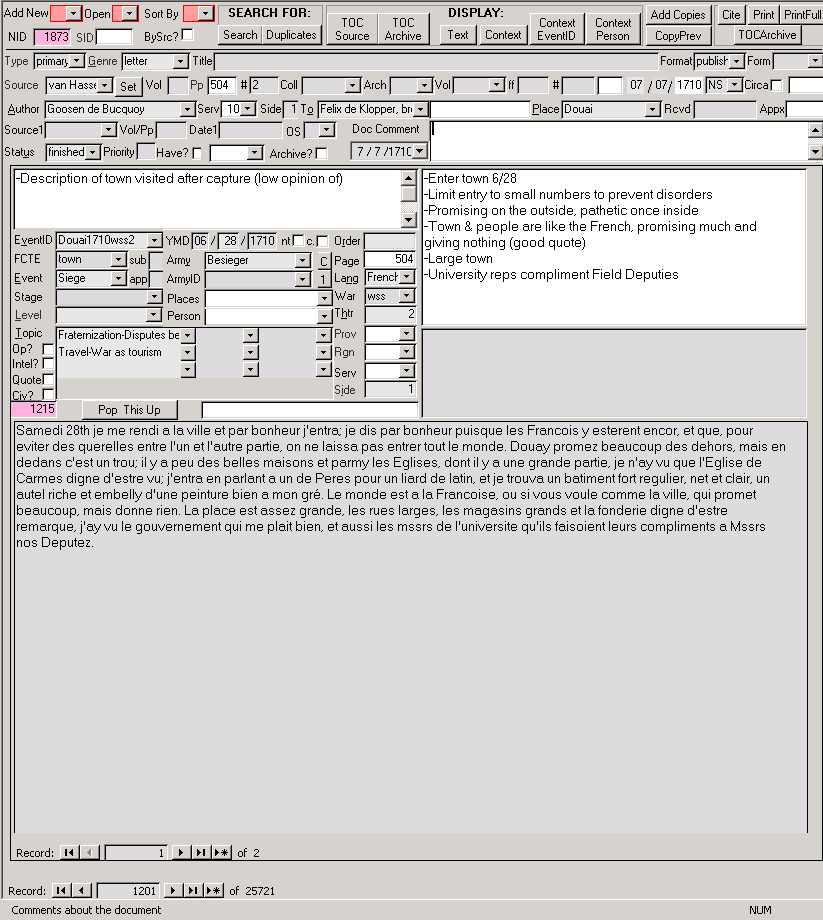
The Notes database keeps track of data at the document level: each "record" in the database is a single historical document, e.g. a letter, a mémoire, a list, a diary, etc. In turn, each document can be divided into an unlimited number of sub-records, each of which can be assigned individualized keywords and codes. For those familiar with relational database theory, click here for a few PowerPoint slides showing a simplified Entity-Relationship diagram of how I have mine set up.
Several things should be immediately evident from the screen shot of the form displayed above. As you can see, I have opted for maximum data density (as Edward Tufte calls it) on the form, so that the all of the fields are displayed when maximized on my monitor. This may perhaps be overwhelming to a new user, but it saves me time and is more efficient than having to navigate between several screens. Additionally, I use keyboard shortcuts wherever possible, in order to avoid wasting time reaching for the mouse. I also make some use of numerical codes, not only to save space on the form, but also so the data can be directly pasted into a statistical program which can then do various analyses. These codes are stored in a separate lookup table where they are associated with the corresponding text value (e.g. Spain = 3, both of which appear in the drop-down combo box so you don't have to memorize the codes), so if there is a need to recode, this can be easily done.
To navigate the form
Notes form: The buttons at the top of the form perform a variety of functions described below. Below the top row of buttons, five rows of fields display information about the source itself (BIBLIOGRAPHIC info or metadata) - you tab across the screen in this section of the form.
Notessub form: The bottom three-quarters of the form (in reality a subform and its associated sub-subforms, as is denoted by the "Record 1 of 2") is for information on the CONTENT of the source: various keyword fields which summarize the content of the source; a Executive Summary memo field which allows you to briefly summarize the source so you don’t have to read all of the transcribed text just to get the gist of the source; a Summary field (allowing 18 pages or so of text) that provides greater detail for your summation of the document; a Comments field where you can make notes to yourself about the document; a hyperlink field which will open up a related file (e.g. an Excel spreadsheet or a scanned image of the original document); and a large Notes memo field where you can type in a transcription of the source. You tab down these columns.
Each of the fields may be left blank or filled in, depending on their relevance to the source (you can of course make any of the fields require a value if you wish). Or you can add new fields or change old ones as needed. All of these items (fields, navigation, lookup values, etc.) can be modified as required.
Below is a table that lists each field (in tab order), its description, and any design issues I've addressed. For those unfamiliar with computerese, fields with drop-down combo boxes are shown in the screen shot as fields having small boxes with downward-pointing arrows on the right - you click on this little arrow and a menu list drops down with items you can choose from. I have developed this database (particularly the Content fields) around my specific research needs, but you can get a general idea of the possibilities regardless of your particular area of interest. Forgive me if I ramble on and give far too specific examples and obvious explanations, but for documentation purposes I want to be able to come back three years from now and see exactly what situations I had already considered with any particular design issue.
Field Label |
Field Description and Use |
|
Bibliographic "meta-data" Fields |
||
| NotesID
(NID) (pink field,top row) |
Number used to uniquely
identify each document (or record). For those unfamiliar with databases, see comments on primary keys below. In the data table itself I have fields that automatically keep track of the creation date of each record as well as the last time it was edited (for accession purporses). See the previous page for its utility as a shorthand in your own work. |
|
| Source | Name of book/article (either title or author, whichever I choose). If the source entered is not in the list, a data entry form pops up which allows you to enter the new Source and its associated information before continuing. Lookup list sorted by alpha. Sets the values for Archive, Collection, OS/NS, Author, Service of Author, Side of Author, Type, Format, and Genre (optional). | Source |
| Set button | Optional. Sets the values for a number of other fields based off of the value in Source (e.g. Author, Recipient, Type of Doc, Format of Doc, Genre...). | |
| Volume | Volume of book (sortable through Sort By combo box). | |
| Pages | Page in book the document starts on. Not a page range, as this value is automatically placed in the Notessub.Page field and you'd have to delete out the extra pages otherwise. Although ideally this would be a numeric field, some pages are Roman numerals (e.g. in a preface), so this field must be text. Code in the Sort By combo box allows it to be sorted numerically however. See design issues below. | |
| Letter Number | Number of letter (sortable through Sort By combo box, since may have "45a" which requires a text field). | |
| Collection | Archival collection (e.g. Additional Manuscripts). You can have additional columns in the drop down list with, for example, a brief description of the years or authors in each collection. | Archive |
| Archive | Archive (e.g. AG) – separating this from Source allows me to include archival info when a book quotes an archival source & I want to record both for future reference. Value can be set by Collection or Source choice (optional). | Archive |
| Volume/Carton | Archival volume or carton number (text data type). You can have additional columns in the drop down list with, for example, a brief description of the years or authors in this volume/carton. | |
| Folios | Folios of document (text data type since can have "v" or "b" in folio). Use the Sort By combo box to sort by this text field. | |
| Number | Number of document (text data type since may need "bis" or 14a). Use the Sort By combo box to sort by this text field. | |
| Order (not shown) | Order of documents: numbers assigned by the user (me) instead of the archives or by autonumber. Useful to keep track of the order of documents in a folder or bundle when the documents are not themselves numbered, e.g. the Dutch Raad van State's incoming correspondence, whose contents are neither numbered by the archivists nor filed in strict chronological order. | |
| Month | Month of source. Separate dates into three fields so Date field can take text and can still sort chronologically with missing date information (e.g. only know year or month and year but not day). | |
| Day | Day of source. Need so Date field can take text and can still sort chronologically with missing date information (e.g. only know year or month and year but not day). | |
| Year | Year of source. Need so Date field can take text and can still sort chronologically with missing date information (e.g. if you only know the year or the month and year but not the day). | |
| OS/NS | Calendar style: Old Style/New Style. I record in Month, Day and Year fields the date written on the letter. Doing this automatically enters in a default date in the Notessub Month, Day, Year fields based on the MDY of the document - it adds 11 days to the date if the document is written in OS, so all dates of content are in NS and can thus be sorted chronologically. When I start moving beyond the period 1700-1715 in my research, I can change the code to vary the number of days to add depending on the year (i.e. add only 10 days in the 17th century). | OS/NS |
| Time (unlabelled) | Time of day document was written, if indicated on document. May be needed if author writes more than one document to the same person that same day. | |
| Circa (not shown) | Checkbox to indicate if letter date is not known or only approximate. When the circa box is checked, the letters c. are automatically entered into the Date field - this way the Cite query will insert "c. " before the date. If the date is known to be before or after the date in MDY rather than just sometime around it, you can put "before " or "after " in the Date field and the code will insert that in the Cite query instead. | |
| Author | Who wrote the document. The standardized name is used (see below for comments). If the person entered is not in the list, you can enter the new Person before continuing. Making this a subform allows multiple authors for a single document. See the Personalities table for comments on streamlining entry of person info. You can have additional columns in the drop down list with, for example, the birth and death dates of this author and even the position/rank the author held at the time the specific document you are recording was written. These are particularly helpful if you have several Dukes of So-and-So but you can't always remember which one was which. As an additional safeguard, it will warn you if the year the document is written is after the author's year of death. | Person |
| Service of Author | Service that author was in (e.g. 20=French, 10=Dutch...). Normally you could just have the database look up the Side associated with the Person (a lookup function), but I need this field independent from Side as some individuals changed sides (even during a war), which must be noted. You might not know when exactly he switched sides, so you can't automatically assign the value off of the date of the letter. Also, you might have an anonymous source but you do know the service, so you need to be able to assign it a value without entering a corresponding author name. Drop-down combo box shows both code and country. Sets value for Side of Author. | Service |
| Side of Author | Side in war that author was on (0=Bourbon, 1=Allies). You might know the side of the person, but not which country he was fighting for, so this needs to be independent of Service. | Service |
| To (Recipient) | Who received the document. If the person entered is not in the list, a data entry form pops up which allows you to enter the new Person and its associated information before continuing. Same drop down list column options as with Author. | Person |
| Place | Place doc written from. If the place entered is not in the list, a data entry form pops up which allows you to enter the new Place and its associated information before continuing. Sets Theater in Notessubform. You can have additional columns in the drop down list with, for example, what county or country a town is in, if there are towns with the same name. | Place |
| Date | Date of document, used when text values are needed (e.g. "after 8/7/1705") or to indicate a date range. | |
| Title of Document | Title of document (e.g. title of a mémoire), book chapter or subheading. | |
| Type of Document | Primary, Secondary or a Thought of mine. Need since this may change in one source: e.g. Mémoires militaires has both a historian's discussion of the war (a secondary source) AND an appendix with published primary documents. In the future I will make a completely separate secondary source notes form, to tailor it to the specific needs of secondary note-taking. | Type |
| Format of Doc | Published, Manuscript, etc. Need since this may change in a single source: e.g. an archive may have both manuscript documents AND printed broadsides or newsletters in the same number/bundle/folder. | Format |
| Form of Doc | Original draft, Secretary's hand, Copy, Quoted in Secondary, etc. | Form |
| Appendix | NotesID (primary key) of document that this record is appended to. For example, Villeroi attaches a petition he received to his letter to Louis XIV. Can jump to that "parent" document by clicking on the binoculars button after the field. | |
| Genre of Doc | The literary genre of the document, e.g. a letter, newspaper, journal, map, état, memoir, list, etc. Not the same as Type of Doc or Format of Doc. | Genre |
| RecvdDate | Date letter received (hidden under calendar). If it was important enough, you could break it up in MDY and OS/NS fields. | |
| Source1 | Source this document bases its info on (e.g. a newspaper quoting another newspaper report - my how times have changed! ;) | Source |
| Vol/Pp1 | Volume & pages of source that this document bases its info on (e.g. a newspaper quoting another newspaper report). | |
| Date1 | Date of source this document bases its info on (e.g. a newspaper quoting another newspaper report). Field rarely used, so I haven't bothered to split them into separate Month, Day and Year fields. | |
| OS/NS1 | Calendar style of source this document bases its info on (e.g. a newspaper quoting another newspaper report). | OS/NS |
| Status of Notes | Ordered from archives, Skimmed, Finished taking notes on it, Get ... | Status |
| Have? | Check this box if I personally have a paper or digital copy of this document. | |
| Have format | What format I have this in: paper copy, microfilm, scanned in, etc. | |
| Archive? | Box is checked if I've consulted the archive copy of this published source (so can cite archive in footnote). | |
| Priority | When in archives & must prioritize docs, I can sort by this to make sure I get the most important documents (hidden under calendar). | Priority |
| Comments
on Document (not shown) |
Put your "editorial" comments on the document here: problems with this document, attributional issues, its poor condition, physical location in the archives, etc. Compare with the Comments field on the Notessub table, which should have comments about the specific content rather than more general comments on the entire document itself. | |
Content Fields |
||
|
NotessubID (NsID)
(pink field, middle) |
Number used to uniquely
identify each passage within a document; one document can have many
subrecords (1 NID to many NsIDs). For those unfamiliar with databases, see comments on primary keys below. See the previous page for its utility as a shorthand in your own work. |
|
| EventID | Each event (siege, battle, etc.) has a unique EventID. I can extract parts of this code to derive the type of event (e.g. the year, the war, the theater, etc.). Can have multiple EventIDs for each subrecord (sub-subform). Format: NameYearWarTheater. E.g. Douai1710wss2. The drop-down list can also display the date (or date range) of the event. | EventID |
| FCTE | Type of fortification event effected (fort, citadel, town, entrenched army). | |
| (FCTE) sub | Subnumber of FCTE, e.g. if town has more than one fort, identify whether event refers to fort1, fort2, etc. Name of each fort appears in the combo box list. | |
| Event | Type of event. Siege, Battle, Amphibious landing, Bombardment, Forage skirmish, etc. Useful when no specific EventID wanted (e.g. a relatively minor action like a forage skirmish). When a theoretical treatise is discussing sieges, I'm not sure whether I should keep Event limited to events that actually occurred (and only use a "Sieges-*" in keyword in the Topic field) or whether I should also put "Siege" here as well. | Event |
| Approach | Siege approach/attack the content refers to. | |
| Army (type) | Besieger, Garrison, Field, Detachment, etc. | Army |
| ArmyID | Primary key of army that the content refers to (keep track of each individual army). | |
| Intelligence? | Is the content based on intelligence from another source (e.g. not witnessed first-hand by the author)? Keep track of whether author of document is witness to events described or simply reporting intelligence received from another source. Can be used to help judge accuracy of source's content, or even allow you to assess more generally how accurate intelligence was to the real situation. When I select any "Intelligence-*" keyword for the Topic field, code behind the form automatically checks this box. With separate "Intelligence-*" topics you can also analyze by subtopics, such as Intelligence-Agent vs. -Deserter vs. -Correspondence intercepted... | |
| Opinion? | Is the content an opinion on the topic? Keep track of whether content is simply narrative or a judgment of what happened. Somewhere there must be a list of common indicator words of opinions (think, believe, expect, doubt, want...) | |
| Quote? (not shown) |
Does this document have a good quote I may want to use in the future? "Oh yeah, there's this good anecdote on eating horses in one of those sieges, but I don't remember which one of the fifty Supplies-Meat-Horsemeat references it is..." - I'm not sure how else to mark such anecdotes. | |
| Level | "Level" of warfare: Administration, Strategy, Operations, Tactics, Logistics, Diplomacy, Civilian, etc. | Level |
| Civilian? | Does the content refer to military-civilian relations? Prefer this to adding Civilian everywhere in the keywords. With code, this is automatically checked after civilian-related keywords have been assigned. | |
| Stage | Stage of Topic (plans, preparations, complete, in process, etc.). For example: Topic=Sieges-Outworks-Covered Way-Assault and Stage=Delayed. Don't know how useful this field is, as you could just add a further subtopic to the keyword string (Sieges-Outworks-Covered Way-Assault-Delayed). | Stage |
| State | Bad, Good, Excellent, Ad hoc, Too strong, Too weak, etc. Don't know how useful this field is, as you could just add a further subtopic to the keyword string (e.g. Siege-Investment-Complete vs. Siege-Investment-Incomplete). | State |
| Month content | Month of content (NOT always same as month of doc's composition: compare the date of the letter in the screen shot above with the date of the letter's content). A letter describing several days would be one NotesID record and several NotessubID subrecords, one for each day, more if you divide each day's content up into separate keyword subrecords as well. | |
| Day content | Day of content (NOT always same as day of composition). If your topic required, you could also add a time or hour field for even finer detail. | |
| Year content | Year of content (NOT always same as year of composition, e.g. memoirs about a long-passed event). | |
| Nite? | Is event that content refers to occurring at night? Important for sieges where much of the activity happens at night, or anywhere they distinguish between day and night occurrences. | |
| Circa | Checkbox to indicate if content date is not known or only approximate. | |
| Topic | Supplies-Bread-Shortage, Sieges-Capitulation-Terms, etc. I have several hundred different topic values (in a compound format similar to Library of Congress headings), and each Notes subrecord can have multiple keywords (a sub-subform). See below for complicated design issues. | Topic |
| Branch | Branch of military involved (artillery, engineers, cavalry...). | Branch |
| Page | Page this NsID passage is on. See below for design issues. | |
| War | War code (e.g. wss=War Spanish Succession). The full name of the war and its start and end dates are displayed in the drop down list for convenience. | War |
| Theater | Theater code (e.g. Spain=3, Italy=4). The names are displayed in the drop down list. | Theater |
| Province | Province code (e.g. 341=Valencia, Spain). Drop-down list shows code and province name. Sets value for Region. | Province |
| Region | Region (e.g. Savoy vs. Venice in Italy). Must separate Theater from Province from Region, since letter may only be referring to Theater or Region. If it was always referring to a Town or Province, you could just have the Province, Region and Theater calculated from the Town, but (unfortunately?) history is far too messy for that. | Theater |
| Side of Subject | What side the content is referring to (for a letter written by a Spaniard about his French allies: Side Author=0, Service Author=30, Side Subject=0, Side Subject=20). | Service |
| Service of Subject | What service the content is referring to (see above example). Drop down list shows code and country. Sets value for Side of Subject. | Service |
| Place Mentioned | Place mentioned in source but neither the Place of composition nor the EventID place (e.g. Heinsius at the Hague writing about Brussels). Multiple places allowed (sub-subform). You could use this to search more quickly and more narrowly for place names than by doing a wildcard search for any references to the place in the Notes field. For example, many of the places mentioned may not be important enough: "John No-one and Fred Nobody stopped at Lille the 5th and continued on their way" is probably not that important if you're interested in Lille's wartime experiences. Drop down list displays county, country, etc. | Place |
| Person Mentioned | Person talked about in source but is neither Author nor Recipient (e.g. Marlborough's opinion of Coehoorn divulged in a letter to Godolphin). Multiple people allowed (sub-subform). Drop down list displays vital statistics, etc. Similar to Place Mentioned, in that you would only use this for subrecords that have some important data on the person and not just a passing reference (which you could find with a custom query). | Person |
| Link | Hyperlink to other files (e.g. Word doc, Excel spreadsheet or graphics image). |
|
| Executive Summary | Cheesy name for the 1-2 sentence summary of the document/passage - when you don't need the details. | |
| Summary of Doc | My summary of the content, so I don’t have to re-read all of the transcription to get the main points. Could also be used to translate difficult text so it doesn't need to be done again (or you could make that a separate field altogether). And given the recent concerns over scholarly plagiarism, this would be a good place to put your paraphrases, keeping the Notes field only for transcriptions. If you wanted, you could even string these together and past them directly into a rough draft. | |
| Comments on Passage | My "editorial" comments on the passage (questions the passage raises, comparisons to be made with other sources...). This comment field is unique to this specific NotessubID; for comments on the document as a whole, use the Comments on Document for the NotesID. For comments or information on the people or events involved (e.g. author, recipient, event...), it would be best to keep that as a separate field in the relevant lookup table (Personalities, EventID) rather than in this field, which should be unique to the content of the passage. | |
| Notes | Transcription; limited to 32 pages of text (65,000 characters) in Access 2002. There is no formatting capability (color, text styles, tables, etc.) here. I'd strongly recommend always writing down the first line or two of each letter verbatim, as this allows you to quickly identify letters you already have notes on, as well as help you identify duplicate documents found in different sources/archives. See design issues below. | |
| Page | When breaking up the content of a document into various notessub records, you can specify what page each subrecord's text starts on. Then you can use that field in a Paste Cite query so that your footnote citation automatically enters the correct page number of that specific passage you are citing (so that you don't have to add in each page number manually once the citation has been pasted in). I keep this field blank unless the document has more than one page, otherwise all your Paste Cite results would have page/folio 1 - unnecessary when there's only one page to begin with. I wish I could think of an elegant way to include a page range when the subrecord spans more than one page. | |
| Language | Language the Notessub
record document is written in (see design issues below) |
|
| Order | Keep track of order of
subrecords so you can reconstitute the original letter as a whole from
the parsed subrecords; default is 1. I made this field so I could just
take a chunk of text out of the middle of a long document, give it its
own subrecord and keyword it accordingly without having to parse and
keyword all the text before it (which would be needed in order to keep
the NotessubID numbers in the proper sort order). See below
for details on how to use it. The field's value is set (current Order incremented by one) by clicking one of the 'Copy current subrecord data to new subrecord' buttons (click here for details). |
With many of the fields (those related to people, places and events), you can have additional information appear in the combo box lists. For example, I display the year of birth and death for each Person-relevant field, as well as the position they held at the time the document was written - that way I will always remember that the Duke of Marlborough was only an Earl in 1702. Collectively these require a minor hit in speed, but nothing noticeable. If you were willing to wait another second or two, you could include more complicated columns in your drop down lists, such as calculating the number of letters this recipient received from this author this year, or whatever else strikes your fancy. However, you can discover all of these things and many, many more by using regular queries or reports, so displaying them in drop down boxes should only be used if they help data entry.
There's also a useful ActiveX control of a drop-down universal calendar (on the upper right-side of the form, shown down, hiding several of the other fields) that came with Access which allows me to find the date of the day of the week a letter gives. For example, when a source says "Last Tuesday we attacked the town and today we finally captured it" and the letter was written on 4/23/1707, I can look in the calendar for the date of the previous Tuesday: the 19th. I then enclose it (as an editorial addition on my part) with [], {}, or <> in the Notes field so I don't have to re-check it the next time.
As a major productivity enhancement, several fields can have their values set by another field (e.g. the corresponding Archive value could be automatically entered once you have chosen an Archive Collection or a Source). I've avoided the problem of overwriting previously-entered correct values with incorrect "default" ones by coding it so that the values will only be assigned if the target field is null (i.e. empty). Also, these values can be overwritten as need be.
On the all-important autonumber primary key fields: For those who are not familiar with database software, primary keys are an essential concept to grasp. The database automatically numbers ("autonumbers") the NID and NsID primary keys sequentially, and uses these unique identifiers as the computer's pointer to specific records, the link to all other tables (e.g. one NotesID record to many NotessubID records). Each record's ID value has no interpretive importance whatsoever (i.e. the NID and NsID numbers have no meaning of themselves), and there will never be a repeating number: if you delete a record, its NotesID number will never be used again. This doesn't matter, however, as you sort the list of records by any field you wish, i.e. do not assume sequential NsIDs come from the same NID, or that sequential NIDs are all from the same archive. You may, for example, have left off taking notes on Marlborough's Letters and Dispatches - the last letter you entered was from 6 June 1704, the NID was 2354 - to turn to a volume of Heinsius's correspondence that is due back at the library in two days. After adding five new records from Heinsius (NIDs 2355-2359), you would later return to continue your note-taking on Marlborough's letters, which would then pick up at NID 2360 on 7 June. To find all Marlborough letters, then, you would filter and/or sort by another field: Source, Month, Day, Year, Author, etc. That said, unless you understand exactly what you're doing, you must NOT change a record's primary key value (there's no need to since it doesn't mean anything) or delete a primary key field from a table. If you are using the NsID field as the foreign key for the Notes table, you must NEVER change them, as you will lose the lose the links between the Notes records and their Notessub records. So be sure to make the control on the Notes form uneditable so you don't accidentally change its value!
Buttons and Search Boxes
The buttons and search boxes at the top of the form perform a number of functions:
The Add New and Open Form combo boxes open up siege database forms that I won't bother going into here, as they are rather specific to my research topic: siege warfare. Suffice it to say that these link my notes database to the quantitative siege database, allowing me to compare variables by source.
The Sort By combo box sorts the records by whichever field is chosen, for fields that are text data type due to the need for letters yet need to be sorted numerically (e.g. Letter number - 10, 10a, 11, 104). This also allows sorting by date, using the Year, Month, and Day fields (splitting the dates up in this way allows for null field values in Month or Day). Sorting dates is particularly difficult with historical sources, as sometimes no precise date is known. Therefore I've made a text field Dates which can take anything from "3/15/1704" to "during the siege of Lille," while the Year, Month and Day fields are numeric, which allow them to be sorted properly. And don't forget the circa checkbox.
The TOCSource button (i.e. Table of Contents of this Source) shows you a list of all the NIDs from this particular Source, with the ability to open up a small window showing any of them you choose. The TOCArchive button does the same, but I suppose I should combine them into a single button someday.
The KWIC button performs a KeyWord-in-Context query - you enter the keyword you want to find and it returns a list of every occurrence of that text string in your Notes fields with the keyword in a central column. The underlying query defines the number of characters to both the left and right of the keyword, which you can of course change. This button is not associated with the current record.
The Context button allows you to see all of the correspondence between the two individuals of the current record. That is, pressing the Context button would show a list of all the records sent from Goosen de Bucquoy to Felix de Klopper and from Felix de Klopper to Goosen de Bucquoy. This allows you to easily find a particular letter referenced in the current record. The more labor-intensive alternative would be to hard-code (i.e. put as text in the Notes field) the NID for each reference. With hyperlinks (HTML) you could make a link to jump to that letter.
The Response button is a more specialized version of the Context button. It allows you to find what the Recipient's response was to the current record - the code behind the button automatically reverses the Author-Recipient pairing (Recipient becomes Author and Author becomes Recipient), makes the date of the letter equal to or greater than the current letter's date, and then sorts the results ascending chronologically.
The ContextEventID button finds all records related to the current EventID (in Notessub subform).
The SearchNotes button opens up the SearchNotes form, which allows queries by any number of fields. A separate form is required since there are many subforms (and sub-subforms) on the Notes form, whose fields cannot be queried together (it's a SQL thang - you need a union query joining the various tables together).
The Cite button concatenates the bibliographic fields (either the fields Source, Volume, Page, and Letter Number OR Archive, Archive Collection, Folios, and Number, plus Author, Recipient, Place written, and Date written) so they can be pasted as a reference into the footnotes of a Word doc. Blank fields are ignored. This is similar to the Copy Formatted command if you are familiar with the bibliographic database program EndNote.
There are two buttons to copy records, one to copy the previous record as a new record, and the other to copy the current record to a new record. You can then change the letter number, folio, date and whatever else is needed.
The Text button combines all the subrecord Notes fields together in a single form, in order to "reconstitute" the original letter after it has been parsed into multiple subrecords according to its content. This also allows you to see much more of the text if needed. You could of course redesign the form completely, making a much larger display for the transcription....
The Duplic button checks all the other records in the database to see if the same document has already been entered in another record. This is automatically done for every new record once the Place field is entered, requiring a second or so for the query to run. For example, I enter a letter of Marlborough's written 6/3/1710 to Heinsius at the town of Douai - this piece of code will alert me if I have already entered a previous letter from this author to this recipient on that date from that place (e.g. it was printed in two different editions). A small pop-up form shows the first few lines of the previously-entered record so you can compare that with the new letter to be entered, hence the earlier suggestion to always enter the first line or two of each letter. The pop-up form is just a warning though, so if Marlborough wrote two letters to Heinsius that day, I can simply close the warning pop-up form and continue entering the second letter. In the future I would like to be able to compare the actual text of documents to see if there are duplicates sent to different recipients. A feature to compare multiple versions (e.g. for siege capitulations published by the different sides involved - are there deviations in the texts?) would probably best be handled by software specifically dedicated to this task. On a basic level, Microsoft's recent Word versions have just such a feature (along with other commenting tools).
The Copies button opens up a separate form which shows where additional copies of this document are located. But see below for design issues that make this a less-than-ideal solution.
On the Notessubform (content fields), a huge time-saver are the two buttons that allow you to copy the current subrecord's data (war, event, side, theater, date of content, language, etc.) to a new subrecord so you don't have to re-enter that information for each subrecord. For example, a siege journal often details the actions on a daily basis - the entire siege journal would be only one NotesID record but many NotessubID records: a 60-day siege would require entering much of the same information at least 60 separate times (a minimum of one subrecord for each day, where you would repeat the EventID, Side of Content...), but the buttons eliminate this - it works even better with the keyboard shortcut I made (Alt-c and Alt-1). One of the buttons copies all the same information to the next record (incrementing the Order number by one), including the date fields (YMD) as is (useful when you want to break up the one day's text into several different keyword themes or Army, EventID, etc.). The other button copies all the information over to a new subrecord but automatically adds one to the day of the previous subrecord, so that you don't have to manually change the day for each new subrecord. With the Order field keeping track of the order of your subrecords (you can go back and change them later of course), you should never use the generic Add New Record button provided with the Navigation buttons, because it won't automatically add one to the last Order number. By breaking the Notessub records down by day (e.g. a letter of June 6 describes events from June1 till the 6th), you can make queries that will list what every source (of all different types - journals, individual letters, memoirs...) said happened on day X, then on X+1, X+2... Essential for close reconstruction of events!
On several forms I also have a PopUp button, which opens up a small movable form with the text from the current record (not Focus). You can pop up many of these and rearrange them around on your screen for comparison, etc.
As column 3 of the Fields table indicates, there are a number of lookup tables which you choose from when you're taking notes. Not only does using lookup tables with combo boxes 1) speed up data entry, 2) allow you to set "default" values in other fields, and 3) ensure data integrity by limiting valid entries, the underlying lookup tables are also useful as forms in their own right. For example, I've got a Personalities table which lists all sorts of biographical information about each individual: names, dates, places of birth and residence, education, family history, even scanned in images of their portraits if they're available. Whatever information you want, you can add it to the table. You can also display these values (or calculations based off of them) in the drop down lists of the relevant fields in your Notes form. In essence this is an entirely separate database, but it uses the Person field to populate several fields (Author, Recipient, Persons Mentioned) in the Notes table.
For those familiar with relational databases, I've tried to enforce referential integrity in these lookup tables in many places, so that modifications and corrections made to the lookup tables will cascade throughout the database, and acceptable values will be limited to the values in the drop-down list. However, I have not done this in a few cases, as I think it works best to be less strict with historical data, since you often don't have full information at the time of your data entry. In a previous version I had not limited the Author or Place field to what is in the lookup table, but now am switching over to limiting entries to those already in the lookup table (once I ferret out all the spelling variations). If you were interested in how many ways Marlborough or Ouwerkerk could be spelled, you'd of course want to alter this. I have code that will ask if I want to automatically add a new entry into the lookup table if it can't find what I've type into the box.
Importing Records from Word (Technical Hints)
As I had already done my archival research and taken many notes on Word before I developed this database, it took me awhile to import all of these Word notes into Access. This is a relatively straightforward process with the Import function of Access, as long as you entered the notes in a standardized format, i.e. each letter was its own paragraph and looked something similar to this: Source<tab>Volume<tab>Page<tab>Number<tab>Date<tab>Author<tab>Recipient<tab>Place<tab>Notes on or transcription of the letter. I did this only to a limited degree (I wasn't completely consistent as I tried to save time taking notes in the archives; the database's productivity features would've been quite useful here), but I still had to clean up the notes before I could import them. I'd estimate it takes 15 minutes on average to clean up 5 pages of notes, but this is a total guess. Use the Replace function in Word with wildcards in order to add the bibliographic info needed - do several iterations, each time adding a delimiter such as a <tab> between each field so it can be directly imported into the correct fields in Access. You'll need to play around with the Replace function to do this right - I used about 5-10 Replace steps, depending on the consistency of my notes in Word. After you've added <tab> stops in between as many fields as you can with Word's Replace, I'd suggest you import the Word files (make it a .txt file first) into Excel, then you can use the Text to Column feature to parse any problematic fields that you couldn't separate with Word's Replace using a delimiter, such as <space>. Also, using Excel makes it easy to add new columns and values for other fields, e.g. Type of Source, OS/NS, and other info that you wouldn't normally record for each document while taking notes; with the AutoFill you can quickly number from 1 to 500 in a few seconds. The entire process takes minutes, but the results in the long run are well worth it. You may still have to clean the data once it's in, checking for any import errors (e.g. I've discovered import errors with letters lacking a day, e.g. 7/1708). Of course, once you've switched over to entering notes directly into the database, you need not worry about the problem of messy data, as you can use all the productivity and validation features mentioned previously.
This can get a little tricky with subtables, where it's a matter of importing the parent table data separately from the subtable data, e.g. Source, Date, etc. fields are Notes table and can go on the same worksheet, but the Author is a subtable since NotesAuthor needs to be a subtable in case of multiple authors. For the subtable data, you need to make sure to assign *known* numeric values to the autonumber primary key. First import the table data, then immediately (i.e. before you enter in any other records that will add additional NotesID numbers) import the subtable data by following this procedure: in Excel make a column for NotesID, go to Access and see where the first just-imported record is, note its NotesID number and then autofill starting with that number back in the Excel subtable worksheet. Since there should only be one Author for each document (at this stage at least) you can make sure that the NotesID numbers of the subrecord match the "parent" NotesID by using autofill. Then Access will automatically link the record in the subtable to the appropriate record in the parent table. Did that make any sense? It's a pain if you have a lot of subtables, but if you want to be able to record multiple Authors for a single document, for example, and have lots of notes already in Word, it's what you'll need to do.
Several issues have arisen as I've put the database through various phases of the research process.
1) I wrestled with the issue of how to deal with documents found in multiple places: for example, the same letter was sent to the Dutch States-General (in ARA SG 5185-1) and separately to the Dutch Grand Pensionary Heinsius (in BH 10:145) as well as to the Raad van State (in ARA RvS 687-1), and might have even been printed in a 19th century journal - or maybe the author will add an extra paragraph in the letter to Heinsius. On the Notes form I have fields to allow both a published source and the archival location on a single record, primarily for when you first encounter a document in a printed source but want to list the archive location so you can look it up later. I also have the Format field allowing me to note that this document in this location is a copy and not the original. I have a Copies pop-up form linked on the NotesID where I can enter other sources which contain the same document, but this is not an optimal solution for primary sources. The problem is that if you want to find/sort all the documents within an archive, these duplicate records won't be included (unless you expand the search query to include that table). So if you want to count all the incoming letters to Heinsius, for example, you have to make a separate record with the meta-data information, and set the NoteStatus field's value to "Duplicate." You should put the text and the keywords in it as well, otherwise you won't be able to search these. You will need to be careful, however, that when you are doing searches or statistical queries on the textual content (text or keywords) that would include both duplicate records (e.g. you're looking in both the RvS and SG archive records), you may need to make NoteStatus = Not "Duplicate" as one of the criteria. If you don't, you'll get inflated values as the same document's content will be counted twice (or however many times that document is duplicated in your database). In one sense this de-normalizes the database somewhat, but the performance penalty isn't that great with today's computers. In short, I haven't figured out the perfect solution yet.
2) Don't forget to make use of the "thought" category in NoteStatus. In addition to noting your thoughts on particular events or keywords, you can make a separate record that gives information or your comments on a source in general, so that you don't have to duplicate the same comments in every record that comes from that source. If you run reports by Source/Archive, you can include this field in the header of the report. You could even have a separate form where you could enter thoughts independent of particular records. I suppose this is like a research journal.
3) If on an upcoming research trip you have a lot of data entry to do and not a lot of time, or in general come across a source that you know you'll want to enter sometime, it might be a good idea to prepare in advance the skeletal records: enter blank "placeholder" records with the bibliographic meta-data (Source/Archive, Year, etc.). If you have the archive's catalog, you would even know how many pieces (or the date range) are in a particular collection, so you could make them in advance: in Excel, make each column its own field, copy the values that stay the same (e.g. Source and Archive fields, perhaps even Author, Recipient and/or Year depending on how the archive volume is organized) and for the ArchiveNumber field number the first few rows (1,2...) and then Autofill down to the last number (if they are foliated, you'd skip this last step unless you know that each document starts on a new page and is only one page long); then you can import these into Access. When it's time to enter the contents, filter by that Source or Archive, then sort by ArchiveNumber, Date, or whatever. You will then have all the generic fields filled in so you can jump straight to entering Dates and taking notes. You can also use Excel to speed up data entry in this way if you have lots of published documents to input with similar repeating fields. It might be best to do this automatically as a matter of course - for every collection you consult, note the total number of records needed and then make blank placeholders for them. This way, you can easily keep track of documents that you have looked at but decided not to take notes on (perhaps a NoteStatus value of "Not relevant" or some such), or you could briefly identify the gist of each document even if you don't take lengthy notes on it. With this strategy, you could also run a query to count the number of topics (or other field of choice) and have a full sample - what was the most important issue for Heinsius? This will obviously expand the size of your database dramatically.
4) Keeping track of pages in the database. This issue is slightly more complicated than it would at first seem. There are at least five different page types that you might conceivably want to keep track of:
I suppose you could also add to these another, where the
original document has no existing pagination/foliation and you have to provide
it yourself, but this fits within the design of the above categories - you
could include a field to mark whether they are paginated in the original or
not if you wished.
Each of these page types has their own utility and my database keeps track
of three of the four (all except the page range, which I probably should have).
The distinction between the Notes.Pages and the Notessub.Page fields is particularly
important for two reasons. First, it allows you to automatically include the
appropriate page in the Cite query (to be inserted into
a Word footnote, for example). Otherwise, you'll only paste the generic page
start (or page range if you prefer), or nothing at all, and have to manually
enter the correct page number for that specific passage, possibly having to
look back to previous NsIDs to find what page they left off with. Second,
with this field you don't have to repeat at the beginning of every Notes field
the page number, in case you divide a page up into several separate NsIDs.
For passages in a single NsID that continue onto the next page, I haven't
come up with any better solution than to simply note it in the Notes field
in brackets: "I saw them [40] the other day. Then we went home"
with the Notessub.Page = 39. If your citation is completely on the next page,
e.g. you quote "Then we went home" in a paper, you will need to
remember to change the footnote citation from p. 39 to p. 40. I can't see
any other way to automate this, unless you wanted to make the Notessub.Page
into a Notessub.PageRange.
Ideally, it might be nice to be able to quickly calculate the number of pages spent on a particular topic, but I'm not at all sure how to do it with this design, perhaps a separate field somehow, or include Notessub.PageStart and Notessub.PageEnd fields? In my Secondary database I have a PageStart and PageEnd field, with a calculated field that automatically does this.
5) The keyword field is quite a poser. Much ink has been spilled (and many pixels darkened) on what is the "best" keywording strategy - librarians apparently get into this kind of thing. I had initially used a strategy common in other databases (e.g. EndNote) where you have one memo field in which you put as many different keywords as you want in no particular order. Unfortunately, this method does not provide adequate precision and consistency on the entry side, two very important features that are required for efficient document-level searching IMHO.
Instead, I have adopted a much more complicated system that attempts to keep track of the many substantive questions I might find of interest about the content of a particular document: who, what, where, when, why and how. Its complexity requires I spell out in detail the logic I used, for my own sanity at least. There are three strategies I have used to provide detail, to ensure that I consistently keyword my records the same way, and to make finding records easy.
First, I have divided the generic Keyword field used by many other programs into many separate fields for each keyword type: separate fields for War, Theater of content, Province, Place of content, (type of) Event, EventID (a specific event), Person mentioned, Army, Side of content, Topic... By dividing up these various sub-types of keywords, I can keep the Topic keyword field constrained to topics and themes rather than having it cluttered with the who, when, and where: with only a single Keyword field, some records might have eight or more keywords covering each of the above mentioned sub-types. You are much more likely to forget to code for one or more of the categories in such a system. I did this all the time in EndNote - forgetting that I not only wanted "France" in the Keywords field but also "Louis XIV" and "17C" and perhaps even "Western Europe." With only "France" and "Louis XIV," to take an example, if I wanted to compare French and English records discussing the 17thC (NB: not just those published in the 17th century) I would have to include every 17th century monarch of both countries in my query in order to find them all. Potentially quite a pain. Much of this keywording overhead can be avoided if when you select the most precise keyword, your code behind the form sets the values of all keywords higher up in the hierarchy. For example: selecting "Louis XIV" sets the Century field to "17C," the Country field to "France," Region to "Western Europe," Continent to "Europe," etc.
Second, for the Topic field itself, which is limited
to topics and themes discussed, I use headings
and subheadings, with a progressively narrower scope. For example: Sieges-Outworks,
Sieges-Outworks-Assault, Sieges-Outworks-Assault-Repulsed. I
did this because I found when combining multiple keyword fields together
or multiple keywords in a single field together to
form one compound keyword, I was unable to keyword consistently.
I have found it much easier to change keywords with update queries (enforcing
referential integrity means these changes are propogated throughout the database
automatically) than to try and remember the combinations of keywords I used
before - we're talking several hundred, quite-detailed keyword strings here.
If I had made separate fields breaking up these keywords (e.g.
KW1=Sieges, KW2=Opinion of, KW3=Criticism, all as one multi-field, compound
keyword), then I could quickly become inconsistent with
my keywording. For example, I might remember to type Sieges (KW1) and
Opinion of (KW2) in many records, but forget on
some occasions that I always want to also record whether the opinion
was critical or complimentary (KW3) - this happens
a lot as you refine your keywords and by habit use
the more familiar outdated keyword groupings instead
of the new ones. It's also useful as you refine your keywords
to make them more specific and discriminating. And it is difficult
to come up with a reasonable number of distinct keyword
"categories" - you might want one keyword for
the general object or topic, a subset of the general object (Artillery-Mortar
vs. Artillery-Howitzer), a judgment on the topic (Sieges-Opinion of-Criticism),
the result or status of (Sieges-Open Trenches-Delayed), and so on. But then
you need to decide: should KW1 always be a
type of event? KW2 an intensifier? Can "Criticism"
appear in either fields KW2
or KW3, depending on how
long the chain is, or would you do it KW1=Sieges, KW2=blank, KW3=Criticism?
The more keywords, the more types of keywords, and the
more detailed the keywords you have, the more complicated it gets.
My solution is to use the first "unit" root
(e.g. Sieges-*) to keep all the related topics together, so if I know
the keyword is about Sieges or Intelligence but I'm not exactly sure how I
phrased the entire compound keyword, I can find the right compound
keyword by simply browsing through the drop down list (since they're sorted
alphabetically) and all the Sieges-* will be together in
alphabetical order. Without a hierarchical
system, if you wanted to search for the more general category, you would either
need to separately add 'Artillery' to every 'Mortar' and 'Howitzer' keyword
field, or else you will need to select all possible types of artillery (mortar,
cannon, howitzer, pierrier, Coehoorn mortar, transport of...) in your query
(the same general concept as the earlier France-Louis XIV-17thC example).
My solution takes a little bit more typing with
this approach, but I think it improves the
accuracy and utility of the coding and querying. You can search for all documents
dealing with Siege-Outworks by searching with a wildcard, e.g. "Siege-Outworks*".
A search of "Siege*" would find all documents with Siege-Outworks,
Siege-Outworks-Assault, and Siege-Outworks-Assault-Repulsed, as well as Siege-Capitulation,
Siege-Investment...
Each record on the NotesKeyword side is one of these hyphen groups.
Example: Marlborough writes in letter A: "a letter of Villars' brought
to me complains bitterly of the garrison's weak defense." In the NotesKeyword
table, record 1 linked to letter A in Notes table is "Sieges-Opinion
of-Criticism"; while NotesKeyword record 2 linked to that
same letter A is "Intelligence-Intercepted correspondence"
- each of these records is one field. This translates into: this letter contains
criticism of one side's conduct of the siege (the side is in the separate
Army field) and the criticism is actually from an intercepted letter that
the author of this document mentions, i.e. Marlborough
himself is not criticizing the defense. These keywords can be searched for
separately or together; there is no inherent relationship between the keywords
in NotesKeyword records 1 and 2. That means that this design makes it difficult
to know when such letters were critcial of one side versus the other, because
you don't necessarily know which Topic the Army field refers to -
the Intelligence keyword or the Sieges keyword?
As a warning, every time you disaggregate keywords
(i.e. add more detailed keyword levels to an already-existing broader
one), you should create it as a new keyword entry (unless you are certain
you've always interpreted "Sieges-Outworks-Assault" as
"Sieges-Outworks-Assault-Repulsed" and never thought about assaults
being successful) and then be sure to go back and recheck all your old generic
records with that old keyword to see whether they should be Sieges-Outworks-Assault-Repulsed
or Sieges-Outworks-Assault-Successful. Otherwise the distinction made with
your newly disaggregated keyword will not be reflected in previously coded
documents.
I have also separated out Stage and Branch from
the Topic field and put them on the same sub-subrecord, so that for a Topic
of "Sieges-Opinion of-Criticism" I can note that the criticism is
of the engineers specifically (Branch), or of the gunners, etc. Or I might
note that the "Sieges-Outworks-Covered way-Assault" was delayed
or in preparation (Stage), whereas a blank Stage value (the default) would
indicate that the assault itself was being discussed. Note that since these
are the same NotesKeyword record, so they are specific to that keyword.
Confused yet?
Third, the search side of the equation becomes more complicated as a result. An important design decision needs to be made - what are the most common types of searches you want to perform? The single Keyword field approach is the best suited for straightforward querying, as you simply put wildcards around each keyword term, so that a query for "*Fortifications*" and "*Intelligence*" would find a record that had a Topic of "Fortifications; Intelligence; Costs." But if you have lots of records on each topic and you want to quickly narrow your search down to a particular one, this is not the way to go.
Separating out the many different sub-types of keywords means that that there is far less need for searching for multiple Topic keywords - and you're reminded to limit your search when seeing the variety of various keyword sub-types. This is important, since such a task is convoluted to do with my setup, as each Topic value, as a subrecord, is its own record.
The results:
| Question |
Fields covering this question (at different levels of detail) |
| Who | Person mentioned, Side of content, Service of content, Army (type), ArmyID, Topic Branch |
| What | Event, EventID, FCTE, FCTEsub, FCTE approach, Intelligence? checkbox |
| When | War, Month, Day, Year (decades and centuries are easy to aggregate with a query like >1699 and <1800) |
| Where | Theater, Region, Province, Place mentioned (town) |
| Why | Opinion? checkbox, some also in Topic keywords |
| How | Event Stage, Topic Stage, some also in Topic keywords |
6) The Notes field. Here are some general issues to consider when taking notes.
If you are having particular trouble reading the handwriting, it might help to mimic the line breaks of the original with a carriage return rather than let the program automatically wrap the text down to the next line - it's easier to follow the words and pick up where you left off this way.
To avoid the possibility of plagiarism charges, limit use of the Notes field to transcriptions only, using the Summary field for your own recapitulations. If you mix your transcribing and summarizing in a single field, be sure to consistently use quotation marks (of course it's easier if you're quoting text in a different language than what you take notes in).
Note more generally that a number of trade-offs need to be balanced in note-taking mentioned here.
Improvements Made
Six shortcomings mentioned in earlier versions of this page and database have been fixed through a combination of code and redesign:
a) Sorting text fields numerically, e.g. Letter number or Page, now done with the Sort By combo box (code courtesy of Liz).
b) I have made the content fields a separate subform (Notessub), so that I can break up a single document (e.g. a letter, a diary...) into multiple subrecords, in order to keyword each passage according to its content or date of content. For example, paragraph 1 discusses the events in Italy (subrecord 1), paragraphs 2-3 discuss the siege of Mons (subrecord 2), and paragraph 4 consists of a request for a promotion.(subrecord 3). As long as you keep the subrecords in the same order, you can always reconstitute the letter (the Text button). These subrecords can also be used to break up a document by day, so that I can compare events on a daily basis, even comparing what each source says happened each day. See Sample Queries for a list of some of the reports I can run with this feature. More simply, you could put your content fields on the Notes table instead of a subtable, but then, you will have to skim through the entire letter to find where it talks about the promotion request.
As the Order field discussion above
indicates, this strategy does have its drawbacks if you are just skimming
through a long document in a record and light upon something that you want
to keyword without first parsing all the text that came before it. There are
several problems to be avoided when you have a long text in a single NsID
(e.g. pasted in from OCR, or you didn't want to parse the document as you
were transcribing it in the archives). You need to keep track of the order
of the subrecords so you can reconstitute the original document, so if you
just cut the relevant passage out of the longer text and make it a new record,
you won't know what was the order of the subrecords in the original document.
You could simply keyword the very long NsID with the codes relevant to that
particular passage, but then you would have to skim through the entire document
to find where exactly the keyword-relevant passage is. The best choice is
to cut the desired passage out of the larger text (e.g. NsID 1), create a
new subrecord for it (NsID 2) and keyword it, then enter an obviously false
Order# for this NsID (e.g. Order#=1000) and note in the larger text subrecord
(back in NsID 1) what that Order# is (e.g. type "{Order# 1000 here}"
or "{NsID 2 here, change its Order#}"). Using this method, when
you are later finishing your parsing of NsID 1, you will be parsing the document
in the correct order (the Order# for NsID 3 - or whatever autonumber
you are on by then - would be 2, NsID 4's Order# = 3, NsID 5's Order# = 4...),
and when come across that notation for NsID 2, you will know to find the NsID
2 record and change its Order from 1000 to the next Order# (e.g. NsID 2's
Order# = 5 since it physically occurs in the original after the text in NsID
5). Then you can continuing to parse the remaining text (NsID 5's Order# =
6...) in order. This is not as easy as simply being able to write the keywords
on page 4 paragraph 3 of a photocopy, but by now you know the other advantages
a digital database gives you over hard copy that far outweigh this minor work-around.
Or, if you used XML, you could just tag the relevant passage of the document
and the order would be kept intact since you are not breaking apart the document,
but the other advantages are worth the tradeoff IMHO. A bit unwieldy perhaps,
but it's not that hard to do once you remember the several steps, and it's
not needed that often anyway.
c) I have made the primary key for individuals an autonumber. See Personalities for the issues.
d) I added a field to
indicate the language
the document is written in. To give one example of its
utility, you might want to find how French-language sources phrased an abstract
concept without knowing the exact text strings used, or perhaps compare French
and Dutch use of a French word (e.g. honneur), or, maybe you just remember
that that great quote was in French instead of English. Ideally you'd
just base the document's language off of the author,
but there are a few complications that I've come across.
First, the recipient or the author's education might demand writing in other
than the mother tongue: the Dutch field deputy Vegelin van Claerbergen
wrote in Dutch to the Raad van State - as all its correspondents
were ordered to do - but wrote in French
to the Dutch raadpensionaris Heinsius.
So you can't assign language with 100% certainty by the service the author
was in (especially given the cosmopolitan travels of early modern European
elites), or even something like their place of birth (in fact, many of the
Dutch-born authors - particularly Frisians - I use appear to have preferred
writing in French over Dutch even to fellow Dutchmen).
You could, however, have code set a default language to save entry time and
change it when needed. I mass updated a lot
of this by first assigning language by Service of Author, and then refined
it (e.g. for the Dutch and English authors who might
write in more than one language) by looking for words in the text that
are unique to a specific language and then update the language field's value
to the appropriate language - assuming the author
didn't use a lot of foreign phrases and you didn't paraphrase in English and
occasionally quote passages in the original language (oops). Or
perhaps better still, you could update it by Recipient, as, for example, the
Raad van State wanted all its correspondence in Dutch.
Occasionally there are even letters written in one language and postscripts
in another: for this reason you should have a Language field on the Notessub
table and have it automatically entered (which could be overwritten as needed)
when you choose the Author. Having a language field is complicated, however,
if the language varied within a single Notessub record (is it worth creating
a Notessub record just to indicate a language change?). This is an example
where XML tags would be better.
e) When doing searches on text in the notes field, the actual text string being queried will appear highlighted within the larger block of text if you use the Find command on the search form (search Anywhere in Field, not Whole Field). The "Next" button will jump from one record to another automatically. The KWIC button described above also helps with this.
f) I've added Circa checkbox fields to both the Notes and Notessub tables, so I can identify if the stated day is approximate or not (e.g. I know the letter was sent shortly after the battle of Ramillies, which took place on 4/25). I can also use this to get less-precise dates to sort in their approximately correct order: c. 3/15 can be interpreted to mean around the middle of the month; c. 3/1 for at the beginning of the month, c. 3/30 for at the end of the month. I suppose you could even break it down further into weeks if you wanted.
g) I've added a higher-level "Executive Summary" field that summarizes the gist of a passage (Notessub record) in a single sentence or two. I was inconsistent in the Summary field whether I should spell out each point, or whether a brief summary would suffice. Not only is this field good for skimming, but you can also include these fields in a search results form, creating a sort of "fisheye" report (see Thomas Landauer's The Trouble with Computers for a brief discussion of this).
Room for Improvement
There are still several minor modifications to be made, and I'm sure this is not the most-efficient organization possible. Overall, however, this database is so useful as I continue to "tweak" it that I'm amazed every time I use it. At this point, it's more a matter of adding new minor features than an overhaul. That and getting the data entered in and coded.
Suggestions or comments on any of this are welcome.
There are, of course, a number of limitations with this type of database. The ideal research tool would reproduce images of the documents (unlikely given most archives' close protection of their holdings), transcribe them into readable, digital text alongside the original handwriting (even difficult-to-read handwriting), translate the text if necessary into a language you understand, and perform automated keywording as well as allow unlimited searching and cross-referencing. Different software packages offer only a small subset of these features, but ultimately the combination of price (free with Office Pro), availability (many manuals, Websites and user groups around) and utility made me choose Access for my own use. Perhaps if there were some standard that hundreds of other historians used and encouraged graduate students to use early in their studies, I might have chosen that instead. But I'm not bitter for having to develop this system on my own (he says with sarcasm). It is incredibly liberating to design a form exactly the way you want it, says the control freak with little sense of design.
Note-taking and SGML/XML/TEI/MEP:
A relatively new type of software using SGML/XML might have real potential
to solve a lot of the issues I've had to deal with in the creation of this
database - search the Web for oodles of sites on these acronyms,
but particularly check out the Historical Event Markup Language at
www.heml.org (not for neophytes). However, from my cursory reading
of the literature thus far, this is still in the future, particularly regarding
the (parsing) software. Additionally, SGML/XML seems wonderful for electronic
editions, publishers and literary analysis dealing with parts of speech
and structures (structural and presentation markup),
but it strikes me as being of little utility for research with the types of
documents I deal with. At the very least numerous additional tags would need
to be developed to mimic the entities easily created
(via fields) in my database. Perhaps I'll become
a convert once an easy-to-use SGML/XML editor is
widely available and a single standard appears (I was initially
skeptical of the utility of electronic databases for note-management! you
know what they say about recent converts being the most fervent) -
only time will tell. From my limited perspective, it seems
that RDBMS also have many other advantages, especially in data entry (see
the examples of field values setting other fields' values in the field descriptions
above). Access 2002 also
lets you export your databases into an XML format, so this will make
converting my existing database much easier if a killer
XML app ever appears. Looking at the Model Editions Partnership (MEP)
guidelines for historical documents based off of the Text Encoding Initiative's
(TEI) XML tags, it turns out that I've already duplicated a lot of their meta-data
tags with my own database fields and I will try
to adopt several more (<gap>, <handShift>, <docketing>,
and <endorsement>) to use within the Notes field (see http://adh.sc.edu/MepGuide.html
for details). It should be relatively easy to export all the fields with the
appropriate tags should I ever need or want to. In any case, converting the
data from a RDBMS to SGML/XML format should not be at all difficult, so don't
use this as an excuse to get started right away.
Note-taking and Transcribing Documents
(a digressive rant)
In the literature on computerized databases and history, much emphasis is
placed on transcribing the full text of the document, in order to not lose
any of the information. In general I would agree with this admonition
(record as much of the information in your note-taking as possible, time permitting),
but purists might criticize me for not transcribing all sources exactly as
they appeared. Sadly, almost every article or book I've seen on the subject
of computers and humanities or scholarly electronic documents is intended
either for those aspiring to produce critical scholarly
editions of works, or for literary scholars who
are much more interested in the semantic structure
of documents than I am (and, I'd think, many other historians
as well), and all seem to assume an amount of time and resources that I know
I will never have. I would make several responses as the "traditional"
lone historian:
1) My database design does an admirable job of saving the textual basis of the quantitative data I create from it, so that we can always return to the source if there is any confusion or contention. Oddly enough, articles from several years ago (circa 1996) acted as if relational databases were incapable of searching text; a concern which software advances have largely eliminated. Similarly, the requirements of archivists and librarians are not necessarily the same as those of historians. So rely only on up-to-date information on software reviews, and don't be disappointed if no one mentions capabilities you want - it may require some effort, but many features can be implemented if you know what you're doing!
2) If we followed the idea of transcribing the source exactly-as-it-is too slavishly, we'd use colons instead of periods in some Dutch correspondence, make a line break at the end of every line in the manuscript, paragraphs would disappear (did the writer start a new paragraph or just not want to start the sentence out at the end of the line? I have no idea), we would have either fragmented words which should be one word or compound words that should be separated, and let's not even start on the whole capitalization thing.... Believe it or not, I'm converting "poffeffion" to "possession"! (This 'f' replacing 's' spelling, which I'd heard was a function of early printing press techniques, even occurred in handwritten English and French!). Some people might very well want to explore my data for that purpose, but frankly most people won't, and I'm not going to do extra work for some hypothetical scholar in the hazy future (assuming I start handing out all of my research notes in the first place). The effort is simply not worth the payoff. Not to mention, the whole issue of copyright and archival materials is still fuzzy to me.
3) I'm rather put off by how such discussions occasionally approach near-worship of THE SOURCE (read with a thundering voice). Keats-Rohan (cited below) argues that translating and standardizing orthography (especially proper nouns) corrupt the data (p69) and should be avoided at all costs. This may make sense for ancient and medieval history, prosopography and literary analysis, but I'm sure many historians have no need to study one particular document (or a few documents) as closely as a literature scholar might study a piece of literature, nor do most historians have multiple versions of long documents to compare, so the concern seems misplaced for many historians. The people I study wrote or dictated ten or more occasionally-repetitious letters every day, after fulfilling their tiring military duties which took up most of their time. I wouldn't expect the language or structure of their letters to require detailed analysis. Ultimately, if someone wants that degree of faithfulness to the original source they are of course welcome to it - others should not, however, feel shamed into providing such detail in their own work if it does not require it. Decide what you need and implement it.
4) Unless we actually have the original document, there are always going to be types of information which even the best electronic edition cannot replicate, at least for the foreseeable future. For example, does a person's handwriting style shift when he writes in French versus Dutch? Even if we could scan images of the original document (archives can be sticklers for copyright), we might need to test the ink or paper to see if the document is a forgery, or perhaps something was scribbled on the back, or an impression of something written on top of the document that is discernible with shading or the proper lighting, or perhaps something was erased, or perhaps the handwriting subtly changed. Art historians and scientists perform these types of analysis on artwork and some documents today, so this is not science fiction; in fact, I found a document in a library that purports to be a long letter written by a contemporary whose provenance I would like to verify. The issue of diminishing returns needs to be addressed, however, and I think the bar has been set far too high by some. But then that's what quotidian historians get when they leave the software development to more literary scholars in the humanities, to the more specialized fields of ancient and medieval history where sources are quite scarce and therefore each one receives lavish amounts of attention, and to managers of large-scale historical research projects - I created my database so I could keep track of too many sources, quite a different problem.
5) Since transcription purists acknowledge that the desirability of complete replication is based on the fact that not every scholar needs the same information from the document, it would seem to make sense that we should spend our efforts maximizing the amount of material made available so as to benefit the greatest number of scholars (i.e. its content), rather than continue past a point of diminishing returns for the few hypothetical future users who would slow down our progress by demanding the ability to analyze a particular document in extreme detail, dealing with grammar or typefaces, for example. We must prioritize, and I'd hope we could widen the offerings of digital history currently available on the web far more, particularly for us early modern Europe partisans (kudos to the Bibliothèque nationale's online Gallica project for going this route, even if they're only scans rather than text). As a cardinal rule, your tools and methods should be determined by your sources and your objective, and history is chock-full of different flavors to choose from, so don't expect any single program to have them all, or for any program to meet the needs of all users, or for any transcription to meet all needs. Hence my preference for knowing the software yourself: customize, man!
6) It's worth noting that those who encourage the use of such strict standards enjoy large-scale institutional support - resources hardly available to most historians, while their material may be interesting but of limited value to the research projects of many historians. Enough institutional support to pay enough scholars to critically examine the millions of documents in archives with the same degree of attention that works by particularly renowned individuals have merited simply does not exist. Time and cost are important in a field like history where there is little money to go around - I think we could spend it more wisely "for the greater good." And for individual scholars and projects of one (like mine), don't let anyone tell you it's better to enter printed documents in manually than to use OCR (perhaps another artifact of constantly-improving software) - with decent OCR software like FineReader, you will save yourself an unimaginable amount of time, even with many 18th and 19th century printed documents. Must be nice for some libraries and private companies to have the money to outsource their data entry to Third World computer "sweatshops"...
7) While much of the raw material of history is document-centric (as composed to data-centric information better served by relational databases), much of the metadata surrounding these textual sources are data-centric. As a perusal of the many fields in my database indicate, the text often forms only the basis for my analysis - the people, places, events, things and concepts in the texts are what interest me just as much, and most of those can be easily "data-fied" (if not quantified) without the need for much methodological concern over lost data in the process, especially when you still have the original text in the Notes field. You obviously need to choose the best tool for your task: I would contend that for many historical tasks, using a readily available and customizable RDBMS allows you to take advantage of the highly data-intensive nature of even purely textual documents, allowing some limited document-centric abilities used by XML within an overall data-centric model. Check out www.rpbourret.com/xml/XMLAndDatabases.htm for an interesting discussion of the differences between the two (written by an XML programmer but with a more general business audience in mind). In early December 2002 the Humanist listserv again discussed the issue, pointing to hybrid relational database-XML approaches.
8) Finally, as a philosophical issue, I would argue that the partisans of the Source overemphasize the dangers of interpreting documents for others - everything we do is an interpretation, but we do it all anyway and most of the time most reasonable people can agree upon a single convincing interpretation (in a well-defined, mutually-agreed upon context), or even a few interpretations for a single document or source. Much of our research is necessarily based on secondary sources, and while I distrust other historians as much as the next scholar (maybe more), we will have to continue this act of faith. To me it's a matter of cost-benefit analysis (or opportunity cost): providing a few new, electronic sources worthy of the title "critical edition," although important and worthwhile, is setting our sights far too low, for there are a few problems with this approach. First, the heavy reliance on a few "canonical" sources will continue to blind us to variations and contradictions in our subjects, often giving us a stereotyped impression - one of the best (and easiest) ways to revise the historiography is to show how less-well-known sources differ from the oft-quoted ones (is Machiavelli representative of most political philosophers of the Renaissance?). More generally, the most important challenge should be to facilitate the easy and more-widespread use of many more digital sources. A few scholars over a century might use the entirety of an 18th century French chevalier's memoirs to analyze its internal structure, but many more scholars might use more mundane parts of that work for their particular research interest: the chevalier's discussion of gender, of sieges, of honor, or of the consumption of potatoes, to name but a few examples. Imagine how far Louis XIV historians would get without the thematic and proper noun indices of Saint-Simon's 41-volume memoirs! In the time it takes to put out the critical edition, scholars could have put out several slightly less-exacting works (which might forego, for example, identifying ever proper noun referred to in the text with a footnoted reference - perhaps linking it to a meta-person index?), with the same amount of money. Reliance on other historians' work is a necessity, but ideally we would be relying on them to provide us with the raw materials from which they fashioned their arguments as much as their more focused, finished scholarship. My point: the literature on historical computing is dominated by the interests of large projects strictly circumscribed usually in time and certainly in geography. Quite understandably, their recommendations are aimed at their peers, something that newbies looking for helpful advice on individual projects like mine need to be constantly reminded of. Just be sure to document and follow rigorous standardization procedures and you should be fine.
To take one example that emphasizes the need for this
everyman-a-digital-historian approach, Keats-Rohan
again seems to limit the utility of historical digital databases by arguing
that attempts to categorize her People (drawn from the Domesday Book and its
variants) by more abstract categories than what exists in the text "fatally
impairs" the reliability of the analysis. Perhaps this is a good idea
for sources which are flawed enough without introducing additional errors,
but this is a bad idea for historians more generally -
unfortunately, it's hard to find any published articles on the kind of quotidian
database I've designed for early modern or modern scholars. That's
exactly what historians do: we all rely on the conclusions of secondary accounts
that are much more filtered than a database assigning modern analytical categories
anachronistically to past societies and events, and there's a large literature
from sociologists and social historians about how to categorize,
for example, class and occupation in order to test modern theories
with past data. If you've ever used an index of a monograph to look for a
particular topic or place, you know how useful an expert's analysis and use
of categories can be (and what additional categories you
wish they included). I have yet to find the comprehensive
printed index, whereas a customizable database such as mine allows just such
a beast - a public electronic edition would allow an additional layer
of added categories found useful by others as well as the original text from
the document. If historians could develop some relatively
standardized set of keywords
(à la Library of Congress but with more detail), a document could be
progressively coded (perhaps even by several people, according to their research
interest) and these codes would then be made available to others. Or you could
even compare different coders' codes historiographically, comment on their
decisions, and choose whichever you prefer, or even modify the codes for your
own purposes. As long as the original document is not altered, I don't see
the problem for the vast majority of historians.
In fact, not coding the text for others actually hinders the
synthetic/comparative history we all should support. Merely transcribing
a source, no matter how painstakingly, does not radically speed up history;
it simply accelerates the storage and transmission of the
raw data, doing little to speed up the processing or analysis of this data
- the most difficult and time-consuming aspect of research. Other historians,
who might be interested in only a particular aspect of a document's content,
will still have to wade through the entire document to find the few kernels
(unless they are fortunate enough to know the exact text strings used to embody
their abstract concept being analyzed), along with the hundreds of other documents
they might have as well - I have tens of thousands of documents to consult,
and hardly the time to analyze the backgrounds of each individual author and
the details of their relationship with the recipient beyond a certain basic
level. Hopefully the editor of the collection will provide the summary you
need without you having to develop your own by going through the author's
entire corpus. Richard Bonney has discussed the wasted energy spent by modern
scholars re-researching various aspects of European fiscal history (www.le.ac.uk/hi/bon/ESFDB/bapres.html),
and Randy Roth has similarly had to redo the archival research of earlier
scholars on colonial American violence rates because of their failure to publish
their raw, disaggregated data. I would argue that qualitative research is
similar to quantitative research in this respect. History would "progress"
more quickly if historians could start at where previous historians left off,
rather than being forced to follow in the exact same footsteps that were already
made by earlier scholars (step 1: look at secondary
bibliographies and footnotes, step 2: go to the
exact same sources in the archives that they did, step
3: take notes on the exact same sources in the archives that they did, and
only then can you start doing something original). And
this might even let undergrads in history start doing useful research much
sooner in their careers. Making electronic versions of these sources
is important, but just as important is to process the information into data
for others. New arrivals can of course disagree with some of the coding or
conclusions of their predecessors, but I'm sure that much of the processing
will remain uncontested (e.g. Who, When, and Where). And
if it is contested, History would also benefit from the transparency
of the methodology used to interpret the documents - we
talk all about historiography but very little about methodology. The
ideal electronic source would allow a personalized
keywording feature, so that you could add your own coding as well as comments
on the coding of others. In fantasyland, every historian would fully examine
the context of every document (in its entirety) that they use, but this is
simply unachievable in reality, assuming we don't want
to give up macro-historical research, and our projects
should be moderated to what would work best for most historians. Robert
Darnton's discussion of the future of the e-book ("The New Age of the
Book" 3/18/1999 at www.nybooks.com)
gives an excellent model: a pyramid made of progressively focused layers,
so those with only a passing interest can skim the top succinct layer (e.g.
you've got to give a lecture on the topic), while others more intimately interested
in the project can delve deeper into layers focusing on themes, documentation,
methodology, debates over the work, etc. My vision is of large-scale historical
theorizing (at the very least, across several centuries or several countries)
that could be based on the entire universe of historical
knowledge represented in databases, rather than being limited to the language,
period and regional horizon of a single historian, as is
too often the case today. The questions historians ask about the past
may differ from generation to generation, but most of the evidence they rely
upon is relatively fixed.
I initiated a brief thread on RDBMS vs. XML on the E-DOCS listserv at the beginning of December 2001, setting out my impressions and asking for feedback. The results confirmed my belief that XML is (currently at least) for research projects with big bucks to spend on data entry and software programmers who are interested in making their research widely-available to many scholars at the same time (e.g. over the Web). For those interested, they can check the discussion logs at H-Net. My database is designed for individual scholars with their own personalized research who cannot rely on such significant funds. A number of examples have been mentioned on the Humanist listserv c. 12/11/2002.
8a) An important related issue that must be addressed
is the Web-centric focus of current digital history. While this is not necessarily
inherent in markup languages' structure, nor is the Web necessarily anathema
to scholarly research (it was created at CERN to facilitate scientific research
after all), most of the discussion of webs and digital history, as well as
many of the examples available online, only go as far as to put their sources
up online and make them searchable. However, I have seen little discussion
thus far as to how these resources are to be best incorporated into broader
scholarly research - in large part this is a function of who is providing
these documents, usually archivists and librarians who must maintain the original
and focus organization and provenance of the sources. Usually, however, historians
have to combine and compare documents from different provenances. Even with
various critical electronic editions online and the many impressive historical
website projects available to date, it is unclear how they can be analyzed
together as part of a larger whole and still retain the advantages
that accrue from their digital nature. Instead, most websites with historical
content seem to be standalone, self-contained sites, making multimedia material
on their site browsable and searchable, but not customizable, while sometimes
their underlying data is even un-exportable. If you want to study the Civil
War experience of two Virginia communities, the University of Virginia's excellent
"The Valley of the Shadow" site at
http://www.iath.virginia.edu/vshadow2/ allows you to search through their
information online and explore the wide range of sources presented (or the
correspondence of Victorian Women Writers, or Charles Darwin...). But could
you write a scholarly research article in a peer-reviewed journal using just
their website? Probably not, for even if peer reviewers would accept a heavy
reliance on web-based sources, the most professional of websites is unlikely
to include all the categories or methods of analysis that should be available
with digital sources: can you, for example, perform simple calculations, such
as adding up the number of casualties (by rank) these two counties suffered
in the Civil War based off their hospital records, or compare the average
number of letters written to X in years A through D, not to mention more complicated
quantitative and qualitative analyses? Only very sophisticated search engines
will allow this (any examples would be greatly appreciated). And what if you
want to compare the Virginia experience of war to that of six other communities
in three other states, whose sources are available on other websites, in published
primary accounts and in various state and local archives? We would have to
replicate the entire retrieval and analytical process separately for each
documentary collection, including the need to return later to the same
sources for new investigations (historical research being an iterative process
after all). Can we save our web-based queries and rerun them as we include
additional sources from other collections? Can we exclude certain cases from
our online queries because we consider them exceptional outliers? Can we recode
the underlying web-based source tagging according to our own criteria, or
add more keywords? The Historical Event Markup Language project (www.heml.org)
hopes to use XML to develop standards whereby a variety of historical content
on websites could be combined to create, among other things, chronologies
and timelines, and while a good idea, it will not be backwards compatible
(i.e. be able to process non-HEML sources), and many of the analytical features
readily available in existing applications from the various humanities quadrants
are, apparently, far in HEML's future, and are dependent on finding interested
and knowledgeable scholars/programmers who are willing to write (most likely
for free) applets to perform them.
My point: The individual historian still needs the ability to manage and manipulate
all these documents whether they are available electronically or not, thus
the need to collect all relevant sources in a single place controlled by
the individual scholar. We cannot expect archivists, web designers and
XML programmers to anticipate or emulate all the analytical methodologies
we may want to use, thus scholars need to have unfettered access to the original
data. Hopefully the digitized documents would be available to be downloaded
(printing them defeats the purpose of having them digitized in the first place
and would require re-entering the data, while even selecting the text off
the website and pasting it into a program might lose any underlying mark-up),
but then you still need to put them into something and fold them in with the
many other types of sources you have collected, which is where a system like
the Notes database comes in.
In contrast, most of the historical websites out there are highly-polished
products geared towards presentation: great public history and useful educational
tools, but not always intended for seriously scholarly historical research,
certainly not maximized for use beyond its own subject matter (HEML might
offer an opportunity to integrate such a variety of websites, but this would
presumably require each site to reformat its material). Am I the only one
to copy text from Websites and put them in a Word doc or in my own database?
Rather than focus on production values (perhaps inevitable given the ever-increasing
multimedia capabilities of the Web), my ideal research-oriented website would
dedicate more of its resources towards making digitized raw sources and the
basic coding of its data available for downloading (tables summarizing the
data with links back to the underlying sources would be good too). Ideally,
after manipulating the raw data, scholars could then upload their own additions
to the website (including the results of the manipulations, new coding, additional
sources, and new information on people and events mentioned in the documents),
but the fundamental need is to be able to fully control digital sources just
as if we had typed them into our own word processor or put marginal comments
or post-it notes in our own books. See the EMWWeb
for my Quixotic attempt to start such a beast. This is certainly possible
in XML; the issue is whether the many web projects using XML-tagged sources
will allow its potential to be realized by making the underlying data available
for further scholarship. The Web will not fulfill its real promise for academia
if it remains limited to bibliographic searches, archive access, email and
the dispersed mass of materials available only in extract via a multitude
of WEbsite-specific queries.
</rant> (a little XML joke)
But back to my database. There are of course a few limitations that it would be nice (although hardly requisite) to eliminate:
A number of improvements are needed particularly for the Notes memo-type field, which might depend on finding Microsoft or third-party utilities such as ActiveX controls. This is one area where HTML/XML-type systems have an advantage, but from my research they cannot come close to Access's many other features such as data entry aids (on the RDBMS vs. XML thread in E-DOCS, no one responded to my question whether XML software could replicate the many useful data entry features of an RDBMS for both textual and semi-quantified sources). Issues with memo fields include:
This is a very limited bibliography of just a few of the works and sites I've found most useful.
I presented a paper on the panel "Databases and the Future of French History" at the November 2000 Western Society for French History conference (at UCLA). Unfortunately, I didn't learn much new there.
Various websites and usenet groups can also be helpful, although you shouldn't expect an expert to create your database for you (at least not without paying them for it first).
I would warn you to be very careful of older discussions (i.e. several years old) on databases, particularly regarding their recommendations for software (for example, someone posted an incorrect warning about Access not handling text fields over 256 characters on the RDBMS vs. XML thread). Although most of the theory of good database design (and implementation for historians) hasn't changed much, database software has changed immensely in the past five years, allowing me to do things in Access that were possible only with "textbases" several years ago. So don't automatically think you can only use textbases or "hypertext" for what you want to do.
Most computer use in history/the humanities seems to be either hard-core quantitative tools on the one hand or qualitative/literary analysis on the other (the humanities quadrangle). Therefore, none of the works that I've read (including most of the XML literature) spend any time talking about the most basic of databases that every researcher can use, like my note-taking one, which is why I created these pages. But if you want to know about how to use databases to examine wills, port records, census data, the structures of your texts, etc., then these works on straightforward relational databases are for you. For database manuals more generally, you have to apply the business concepts/examples discussed in the manuals to your, often quite different, needs - not always an easy thing to do.
My immense thanks must go to my programmer/analyst wife, whose knowledge of VBA and database theory is far greater than mine, and who has given much of her time working on the coding for some of these advanced features.
Last Updated May 30, 2005 3:43 PM