|
Gateway to the Early Modern World |
Gateway |
Research |
|
|
My Database Adventure
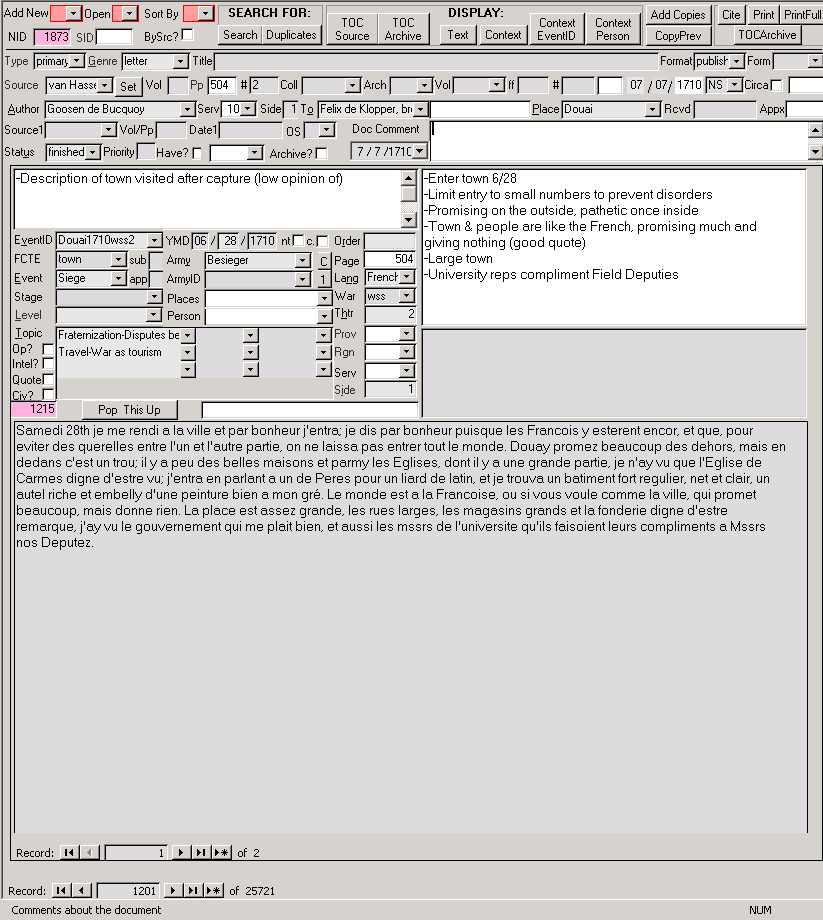
This is a slightly out-dated screen shot of my Notes database (created in Microsoft Access, a relational database application). I now use this database to take and manage all my primary and secondary source notes, having already imported my old notes from Microsoft Word into Access. What follows is my personal take on the usefulness of relational databases for note-taking and note-management (in historical research particularly), as well as a description of my database and why I designed it the way I did. I’d appreciate any comments or suggestions for improvements. These web pages were written half for your benefit (to spread the gospel) and half for mine (to document a lot of the often-complicated design issues I've faced over several years); hence you will see me wavering back-and-forth between "I can do this" and "you can do this" with no particular rhythm. All of my comments below should be applicable to most relation database management systems (RDBMS) and some to any word processing.
General comments
This database fills an important
void between currently existing software, the four corners of the humanities
database "rectangle": in one quadrant is relatively straightforward
text-retrieval software (e.g. askSam,
Scribe, TakeNote!)
used to keep track of documents and their content;
in another quadrant is textual/literary analysis software which foc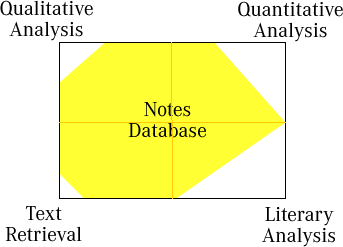 uses
on analyzing the language of documents (TACT);
in a third quadrant is quantitative analysis (statistical programs such
as Minitab and SPSS); and in the fourth quadrant
are qualitative data analysis (QDA) programs created for the social
sciences, which focus on coding and "theory-building" (Atlas.ti,
QSR's N5/Nudist and Ethnograph to name a few)
- I suppose you could include network analysis here as well (Social
Network Analysis using mapping programs like
InFlow). My Notes database inhabits a middle region between these
four points, sharing most of the features of text-retrieval packages,
many of the features of the QA packages, some of the features of quantitative
analysis, but very few of the features used for literary analysis (word
frequencies, keywords-in-context or KWIC, grammatical
analysis, stylometry, etc.). Importantly,
the database also includes a bibliographic database that allows me to
manage citations of secondary sources in addition to notes taken on
primary works in the Notes database, providing many but not all of the
features available in products like EndNote and ProCite. In toto, this
integrated database focuses on the "traditional
art" of historical research and writing. Given
the bad press History has received lately (e.g. recent plagiarism cases
and the brouhaha over Arming America), the discipline as a whole
could undoubtedly use more rigorous research methods. This note management
database provides one possible solution. [A 17 December 2004 Chronicle
of Higher Education special report on plagiarism mentions several recent
examples] uses
on analyzing the language of documents (TACT);
in a third quadrant is quantitative analysis (statistical programs such
as Minitab and SPSS); and in the fourth quadrant
are qualitative data analysis (QDA) programs created for the social
sciences, which focus on coding and "theory-building" (Atlas.ti,
QSR's N5/Nudist and Ethnograph to name a few)
- I suppose you could include network analysis here as well (Social
Network Analysis using mapping programs like
InFlow). My Notes database inhabits a middle region between these
four points, sharing most of the features of text-retrieval packages,
many of the features of the QA packages, some of the features of quantitative
analysis, but very few of the features used for literary analysis (word
frequencies, keywords-in-context or KWIC, grammatical
analysis, stylometry, etc.). Importantly,
the database also includes a bibliographic database that allows me to
manage citations of secondary sources in addition to notes taken on
primary works in the Notes database, providing many but not all of the
features available in products like EndNote and ProCite. In toto, this
integrated database focuses on the "traditional
art" of historical research and writing. Given
the bad press History has received lately (e.g. recent plagiarism cases
and the brouhaha over Arming America), the discipline as a whole
could undoubtedly use more rigorous research methods. This note management
database provides one possible solution. [A 17 December 2004 Chronicle
of Higher Education special report on plagiarism mentions several recent
examples] |
The database helps throughout the entire research and writing process:
Broadly speaking, this note management database allows the user to:
Step 1: Researching and Note-taking
This database replaces traditional note-taking, whether it be simply typing up source documents or notes in a word processor program, coming up with complicated directory and file systems on the computer, or even using the old-fashioned notecard/file cabinet systems. This system is much more efficient, particularly when you can enter the information directly into the database (e.g. using a laptop computer in the archives). This project began when I started to write my dissertation and I tried to develop an organized system (I'm an organization fanatic, to the point of preferring that to actually doing the work) with my Microsoft Word notes and couldn't come up with a flexible yet simple system that allowed me to manage my thousands of documents: update old notes, add new ones, as well as organize, search and retrieve them all by several different categories at the same time. Even with VBA code in Word I was unhappy with the results, and after looking into various text-retrieval and qualitative analysis software and asking questions and reading in journals, books, on the Web, and in Usenet groups, I was unwilling to pay several hundred dollars to buy and learn to use a new system which wasn't really what I wanted (e.g. askSam). Furthermore, I want to control the database myself and be able to tweak it on a whim rather than rely on pre-packaged programs and pray that the next release will include the feature I'm dying to have, so I decided to learn relational databases, starting with Access 97 in particular.
The Secondary database (detailed description to come) provides a place to store bibliographic information on the thousands of scholarly works you will come across in your research. Consulting the various online library catalogs and bibliographic aids, you can keep track of what books you need to check out and articles to read, what the status is of each (did I interlibrary loan it already and when? when is it due? have I photocopied it or taken notes on the relevant passages?), as well as keep notes on their content, even paste in abstracts from Historical Abstracts and other online sources. I used to use EndNote and was very pleased with it, but now that I have created my own version, I like many aspects of it much better, although there are a few minor features I wouldn't mind implementing in Access if I knew how. But "if wishes were horses..." as my grandmother used to say...
The Notes database
is dedicated to primary sources, and works best when
dealing with shorter documents or
long documents that
are easily parsed into smaller components – since I
rely heavily on correspondence, it is ideal for this (the Notes memo field can
take up to approximately 32 pages of text - 65,000
characters). If you analyze much longer documents that are not easily divisible
or are firmly planted in one of the corners of the
humanities rectangle, you should use other software, particularly if you wish
to do hard-core quantitative, qualitative or literary analysis. RDBMS can also
be used to record data from quantitative sources (preferable to Excel in many
cases), as you can create unique entry forms customized to a specific type of
document. For example, you can create a totally separate data entry form to
mirror each document type you have - orders of battle, états of troop
reviews to mention a few that I use. You can then export this information (via
a query) into a dedicated statistical package, such as Minitab, for further
analysis. You can also link your records to images, so that you can, for example,
pop up portraits of people in your Personalities
table, or scanned-in images of siege plans and fortifications.
This database is designed to be used on the computer – taking
notes on sources, recording and retrieving data, and as quick retrieval for
notes and text during the conceptual and writing stages of a project. As a last resort,
you could print off a blank copy of the form to fill out in the archives (or save the form
as a report to avoid printing the gray background), although obviously entering the notes
directly into the computer is much more efficient. You can, of course, print out what
information from this form if you wish, in whatever format
you desire, using reports.
The Secondary and Primary databases have several significant advantages over traditional note-taking systems:
a) Speeded up data-entry. There are several components to this:
b) Provides more accurate data entry which allows more accurate searches and retrievals. Many fields can only take certain types of values or data types (validation rules) and others are limited to the values in the lookup tables, so misspellings of names and text in numeric fields, for example, are avoided. And you'll be unable to forget to note an important piece of info about the source when you require entry for that field, i.e. the database will not let you leave the current record until you enter a value. Using combo boxes allows fast entry and provides data validation, so that you don't misspell common entries. You can also use these drop down lists to display additional information as memory aides: if you are not sure which prince of Hesse-Cassel the recipient is, your memory might be jogged by the year of birth and death of each, as well as rank of the recipient at the time the letter was written, all of which can be displayed in the combo box list.
c) Quickly makes changes to any number of records. For example, I spelled the French secretary of war’s name "Chamillart" – actually I just typed in "ch" and the lookup entered in "Chamillart." If it turns out it should have been Chamillard, I make a simple update query to change all the occurrences of Chamillart to Chamillard. (This is actually a bad example, in that I would just change the spelling of the name in the Author lookup table, and with referential integrity enforced all occurrences would automatically be changed, but you get the idea) You can also do mass updates on partial text strings within a field (e.g. in the Notes field, convert all my abbreviations of "p-e" to "peut-être").
d) Ability to prioritize research goals. With the database's Priority field, I can identify in advance the priority I should give to various documents during a research trip (or when entering a lot of data in a limited period of time). This way, you can focus your efforts on the highest priority items, leaving less important items for the end of your research trip.
e) Gives you a unique reference number identifying each document, that can be used to quickly find the document in the database. As a result of the autonumber primary key, you can refer to any document/record anywhere (in a chapter draft, on a map, in a table) by simply noting its number rather than having to write out the Source/Archive, Author, Title, Volume and Page number. For example: any time you print off a document from microfilm or get a photocopy of a document, you simply enter a new record in the database with the basic bibliographic information so you only have to write that NotesID number (as I term the reference number) of 1-5 digits on the print-out - 13245 instead of BH 5:234 #200. When you want to enter in the transcription and other data later, you simply search the database for the NotesID number written on the print-out. If you have long documents broken down into multiple Notes subrecords, you should also note the NsID so you don't have to go skimming through them all to find the relevant subrecord, e.g. 13245-15034.
Step 2: Analysis and Keywords
In the analysis stage, you can categorize your notes and sources according to any number of variables. Once all the notes (or at least enough of your sources) have been entered into the database, the second step focuses on analyzing the data by summarizing, keywording, and coding the data in the documents, as well as combining the various sources into publishable scholarship. This database is designed for just such a task: managing and analyzing your notes and documents. With notecards or hardcopy, your keywording and analysis can be awkward and require much time. You either have to take your notes directly on small notecards (a clumsy process with hundred of cards to keep track of) or take notes on paper/computer and later (virtually or physically) cut and paste them onto notecards, writing the same (source) information on the top of each card in the case of notecards. Perhaps you need to make multiple photocopies of them in order to cross-reference them. After you have divided them all up and keyworded them, you can then use them to do searches by keyword. But unfortunately, you suffer from several problems: you have to reorganize all your sources every time you do a new query (not to mention the additional effort if you want to return them to their original "default" order); you are severely limited in the number and length of categories you can code your cards by (how many color codes and keywords can you fit on the top of paper, ranging from 5" to 8.5" wide?); and you are extremely limited when trying to sort by several categories at the same time, being forced to go through several sorting iterations (first by year, then by theater within that year, then by side of author within that...). From my preliminary research, a RDBMS like Access performs all of these tasks marvelously.
To give a ridiculously-complex theoretical example that is intended only to illustrate the flexibility and speed such a database offers - where the computer does most of the work for you once you've set up the database and entered and coded the data (tasks you have to do no matter what system you use) - I could in a matter of a minute or two find every text fragment out of tens of thousands of documents that met all of the following criteria:
The resulting computerized note database offers several features. It:
a) Differs most significantly from existing bibliographic databases in its ability to focus in on the fine details of individual documents (the document level), rather than remain on the collection level (where you cannot easily subdivide a book chapter, article or archive volume). By focusing on the document level, each document can be sub-divided into an almost infinite number of subrecords, each of which can be assigned separate keywords. With this structure, you can identify just that portion of a document that refers to the topic under consideration, rather than having to skim through a page or more of a document in order to find the relevant section. If you need to widen your perspective, you can easily view the surrounding text for context. With detailed keyword categories, you can record and query your sources with as detailed a coding scheme as you want to create, far more finely grained than what is available in most bibliographic databases, which will pull up only the entire source or document. In this sense, it comes far closer to the notecard method of dividing up a single document into multiple cards, depending on the keyword categories you use (e.g. one card for bibliographic info, one for the first paragraph discussing the army movements of the last week, another card for the next paragraph describing details of the siege, etc.). You can even print these "cards" out as hard copy onto real notecards - legible, non-fading, non-smudging notes that can be reprinted in a few seconds (trade 'em with your friends!).
b) Allows you to keyword and code your sources in a number of ways. Ideally, much of the keywording could be done automatically with a mass update query, but you should obviously read through all of your sources as well. Although I have tailored my database to my specific research interests, you could easily adapt it to your own purposes, assuming you know how to use the software and understanding good relational database design. See the description of the various fields for details on the variety of ways in which I can keyword the sources entered into the database, including both qualitative and quantitative coding. You can also summarize the content of your documents (using the Summary field), giving a brief synopsis of a document so that you don't have to reread the entire document every time you come across it - separating transcriptions of the sources from your paraphrases would decrease the likelihood plagiarism accusations.
c) Makes all your notes quickly searchable (text retrieval). This is the most amazing part of the database. The querying capabilities are extremely powerful, especially when you break your notes down into separate fields for greater granularity. You can search as well as sort by any number of fields, with any values you choose (actual values, greater than/less than, Boolean operators, wildcard characters, etc.). Since I've included a number of topical fields, you can combine criteria from several of these fields in a single query. For example, if I wanted to know what the French thought about sieges in the Iberian theater in the wake of the battle of Almansa, I could within seconds call up all documents (records) in which they (Service of Author = France) talk about sieges (Event= Sieges) in Spain (Theater) after Almansa (Date = >4/25/1707, the date of the battle).
The ability to search for text strings within a single field is particularly helpful when you are trying to find information which you had not initially thought important enough to remember or mark - place names and minor personages in the Notes field are of course the most obvious example. Here's the example that made me a zealous convert: I was trying to map the state of fortifications in Flanders during the 1706 campaign and there were several towns that I thought had decent fortifications but I wasn't sure. I needed contemporary discussions of the state of their fortifications, but had no idea in which of the hundred possible sources (thousands of documents) I might find them - this sort of information would not be limited to a particular type of source (individual, nation, rank...) or archive. Even worse, I haven't yet keyworded all my notes, so I couldn't call up the keyword "Fortifications" and look through the hundreds of records that would have appeared. Instead, I did a wildcard search for the name of each town I was unsure of (e.g. "*Maubeuge*") in the Notes memo field and within 15 seconds 15,000 records had been searched and 50-odd records appeared which had the word "Maubeuge" anywhere in the the Notes field - this with my old 333 MHz 64 MB RAM computer running Access 97. I simply would not have attempted to find this information without the database - it would've taken days to search through every possible document, probably several hours even if I was using the search function looking through a hundred Word files. And note that I was able to do this without any time spent processing the data, i.e. coding or keywording. Then multiply this by the eight or so towns I needed to look up. Of course it is important to code and keyword your entries since the source will not always explicitly mention your categories (especially abstract topical categories such as logistics), but you can see the utility of even such a bare-bones database.
Given the time needed to import your old notes, it is imperative that you convert to a database as soon as possible. At the very least, start taking notes on the computer in a consistent format immediately (use tabs to separate different 'fields' in a word processor), and slowly work to get all of your notes/transcriptions on the computer too. Waiting a few years may get you better software, but it won't make it any easier to import non-standardized notes and you'll have another few years' worth of handwritten notes to import/enter. I wish I had done this several years ago, although I don't know if the software had its current capabilities at that stage.
If transcribing all your documents into the computer
seems too daunting a task, you could still take advantage of many of the database's
features by using it as an extremely fast card-catalog indexing system
(offline indexing), but with more detailed keywords
constructed to suit your needs. Don't enter your transcriptions into
the database, but still use the bibliographic and keyword fields - something
akin to a bibliographic database program such as EndNote, which (as far as
research is concerned) is only a pointer to the appropriate work (and
even location on the page) to then be consulted. This
setup differs from a bibliographic database program, however, in that the
index operates on the document-level rather than the book-level (or collection-level
in the archives), with the ability to look for text fragments within a letter.
With a program like EndNote, you can find all the articles that deal with
Topic X, but even if you take notes in the Notes field it's rather difficult
to find quickly just the specific passages in an article or letter than deal
with Topic X, much less do complicated queries on all records with that Topic.
In this scheme, you could include a field in the
Notes database (call it "Filed Under")
that would indicate where in your own filing system the notes can be found
for the appropriate record. If you have your notes in a computer
file or an image of the original scanned in already, you could also
use the hyperlink field to jump automatically to the file (or the bookmarked
section of the text, or even display the scanned document
in a linked field on the form) once you've found it through a query.
You wouldn't be able to search the text itself (although
you possibly might be able to search the opened Word doc with some VBA code),
but it still might be a significant improvement over shuffling through papers,
note cards, and text files. And of course you could start taking notes in
the Notes field for all new sources, slowly entering in
old notes as needed.
You can also use the database to keep track of "documents" that
can't be typed into the Notes field. For example, maps can each have their
own record (with a link to the scanned-in image if you want) so that you can
assign a primary key ID number to each, as well as keyword their content so
you can call them up when doing searches.
The database also has the very important advantage of making sure that you find EVERY occurrence of topic X that you're looking for, and not just the ones that you remember offhand. This will help keep us intellectually honest, as we're all more likely to remember and look for the cases that support our theories rather than those that disprove them (as cognitive psychologists have shown time and again). I'd like to think Michael Bellesiles of Arming America fame/infamy would have discovered many examples of "gun" or "musket" or "rifle" (and associated synonyms) in early American sources had he searched digitized versions of these sources, not to mention the ability to create a database to keep track of probate records.
Click here to see a list of queries and reports you can make with a database like this.
Step 3: Writing
In the composition stage, you need to write up all of your analysis and provide the documentary evidence you have built up to support it. There are several features of the Secondary and Notes databases that speed up the writing process and give you the ability to easily trace your analytical process. To this end, the Secondary and Notes database:
a) Allows you to summarize the content of your textual
sources dealing with a particular topic, event or person. To take a
simplified example, I am writing a narrative of the siege of Douai in 1710,
which lasted two months. With the database, once I have coded the documents
I can sort all the sources by day so as to compare all the accounts of what
happened on a particular day. Using a query (or query-based
report), I can then compare each source for day X side-by-side, making
comments on the reliability of each source if necessary. After corroborating
sources and coming up with a convincing description of what actually happened
that day, I could then write a brief narrative of
that day's events; I could even
string these narratives together for a rough draft
narrative of the entire siege (even pasting them directly into Word
and then editing them for cohesion). Whenever I go back to look at that event
(if I'm revisiting the issue, rewriting the chapter, or have been challenged
on a point, etc.), I will immediately see all of the sources that were used
in its construction and my comments on their reliability, including how
I came to the conclusion I did, i.e.
why I believed source X over source Y. Using this type of system, I can keep
track of how I came to write a particular statement, rather than
having to redo all the work in between (the path from the
raw sources to the final written product)
and trying to figure out why I said X instead of Y. Now if only I actually
followed through with this good idea!
Click here (to come) to see a screen shot of the form I have created for this
purpose, as well as an explanation of its construction. I have tried to design
this form so that all the essential features for writing a paper are present
on one screen. If you prefer, you could print this form
out as a report, or could make one of your own design.
Note that this type of summary deals with multiple documents on the same topic
or event, contrasted with the Summary field mentioned above, which only summarizes
the contents of one particular document.
If you want to replicate the ability to look at multiple notes at the same
time (e.g. notecards spread on your desk), in addition to a form that would
display parts of various sources, you could also write code that will display
various sources in separate windows that you can then resize and move around
on your screen. Or, if you prefer, you can print off notecards of the sources
once you have queried and sorted according to your criteria. In the future,
electronic paper will hopefully make it possible to replicate this exactly,
but with the advantages of digital sources.
b) Allows you to make any number of impromptu keyword searches on a specific topic, e.g. pulling up all the documents on dealing with Allied logistics in Brabant when the thought strikes you. You can then assign a separate "thought" record that holds your thoughts on the topic, although I might create a form similar to the ByDay form mentioned above for topics in order to record my thoughts on each document.
c) Makes calculations from the various fields. This is more important in my siege database where I have many types of numeric data, e.g. lengths to derive from dates, but I could, in the Notes database for example, count the number of letters from person A to person B, the number of letters written in a particular time period, etc. See Sample Queries for examples.
d) Lets you use the unique NotesID number while composing your text, quite handy for saving space and speeding up querying for specific documents. If you are writing and have a serendipitous revelation while reading a specific document but don't want to distract yourself with the tangent at the moment, you can simply jot down a few words along with the NotesID number (as well as adding keywords to the record) and any thoughts in the Comments field, allowing yourself to go back to it later. I also keep the NotesID numbers in the footnotes of my drafts so it's easy to quickly look up those records in the database if I need to go back to check the source when editing the paper, or if I am considering a different nuance to the quote, or if someone challenges my interpretation of the source. If you need to compare several sources in the same footnote, or want to go back and check on the wording of the quote to see if it fits your slightly-revised interpretation, you can simply type in that NotesID number instead of typing all the bibliographic information (Source, Volume, Page, Number...) to find the document. If you include the NotessubID number (see later for the division of a document into the bibliographic Notes meta-data and the content Notessub data), you can also go directly to the proper subrecord - handy since a 100-page journal of an entire campaign would only be one Notes record with perhaps a hundred different Notessub records (one for each day or topic) to skim through. If you mark off these reference numbers in your text, you can delete them all at the end, or better yet hide them so they don't print, but they'll still be available in the future to you. Whenever I make notes to myself during composition, I use curly brackets "{}" to identify them, so I always know to search for "{" and "}" before I print off a finished draft. You can use the same markers for these reference numbers, or probably different ones in order to search for the two categories separately. You could also use such shorthand references on your draft maps: identifying the sources for certain features by writing the NotesID number (1-5 digits) instead of trying to fit a longer a longer Source, Volume, Page, Number on the image.
e) Provides the minor, but still very useful, ability to quickly paste citation information to your Word document (both Notes and Secondary records). Once you find the specific record or work you want to use in a paper, you can click a button which copies its essential bibliographic information into a query which can then be pasted into the footnote of your text document (saving you from having to type it all out). This is similar to EndNote's Copy Formatted command, and will save you many hours of typing and later searching for incomplete or missing footnote citations.
You can also run a variety of reports off the database, displaying whatever fields in whatever format you chose. For examples, see Sample Queries.
The database also has a number of miscellaneous advantages over traditional paper-based note systems:
a) It's Portable. Put your database on a disk (probably a CD-R/W or flash drive, as the database will take up tens of megabytes of space if you have many forms and lots of memo fields) or keep it on your laptop and you can take it with you wherever you go - to the archives in a foreign land, on vacation, to conferences, in your seminar classroom, to your oral defense, etc. It's also useful if you're tired of having notes spread all over your desk since you can have several documents or instances of the forms/database open at the same time, although my desk is perpetually piled with papers anyway (see Sellen and Harper for some good reasons for this). And I try to have hardcopies of my notes as well, just in case, although this is impossible now as I currently have over 20,000 records in the database and several filing cabinets full of paper copy already. If you prefer, you could print out the resulting queries (as reports) in order to spread them about you as you compose. In either case, with the computer all of your notes in the database are now available for you to edit, peruse, or add to as you wish when you're away from home or the office. Imagine having your ENTIRE set of notes on ALL of your primary and secondary sources all on one CD wherever you are, and quickly searchable! Portability also means backups are simple (you don't have to select zillions of files or documents to backup, just one single database file) and you can have several backup copies in various places - at home, at the office, in a security deposit box - to ensure the safety of all your precious data when accidents happen. No more need you fear that your reams of paper notes and yards of notecards will be stolen, damaged by flood, or consumed in a fire. If you had the inclination and knowledge, you could even put your database up on the Web to share with others, or at least access it yourself over the Web (MS Access and probably many other RDBMSs have functions to make posting your databases up to the Web relatively easy, assuming you have the right ISP). If you divide your database into a front-end (the interface forms that display your data) and a back-end (where the actual data tables are located), you can have separately-sized forms configured for both your desktop and laptop. My laptop has a 14" display but my desktop is 17", so I use more space (e.g. allowing more of the Notes field to be displayed) on my desktop front-end version. Then you just transfer your back-end database file between the two, always remembering to synchronize the two so you don't overwrite the most recent version with an older one.
b) It's Flexible. If you are computer literate, I would highly recommend at least considering creating your own database. The flexibility and power you have with a program like Access is amazing: you can make any changes to it you want, rather than being forced to conform your work to other people's ideas of what you should be doing. This database has obviously been tailored to my specific needs, but if you know Access (or any other database software), you can adopt many of these ideas to fit your own requirements (assuming you don't need all the functions from one of the other "quadrants"). If you need to create a data entry form (a "transcription template") for a new type of document you've discovered in the archives one day (e.g. an order of battle, a port book, a judicial interrogation, or any other series of documents whose formats and data are somewhat standardized), you can do it on the spot, or that very night so it's ready for the archives the next day. You can create any type of reference lists you might like (people, institutions, definitions, regiments, etc.) that can keep basic information on them available for quick look up. You can also mimic features found in other software, or implement a new idea when it hits you. It is very powerful!
As a specific example of the flexibility, some archives now offer scanned images of archival documents on CD-ROM. Instead of using a graphics program to open each "page" separately - after transcribing the page, close the current file and then find the next page file to open (do that for 2000 pages!) - you could design a form that will display your Notes form alongside a large field that displays a linked graphic file. You should also be able to program a button that would automatically look up the next or previous file (take open file's name - e.g. rvs102.tif - and open up the file after adding or subtracting one to the last digit, or rvs103.tif). Additionally, you won't have to alt-tab back and forth between the graphics window and the Notes database, transcribing one line at a time (or however much you can remember at once). You get the idea.
These immense advantages do come at a price however:
1) You've got to have the software obviously (Access comes with the Professional version of Microsoft Office, which is an extremely good buy with the educational discount).
2) You've got to learn how to use the software. This may be the most difficult and time-consuming part of the process, with only the process of transferring your existing paper or non-database computerized notes into the database a contender for time required. Many of the features of my database took a day or more for me to master (I literally knew nothing about RDBMS beyond how to use the bibliographic database program EndNote before I started working on it), primarily those dealing with increasing productivity in data entry (which should be encouraging to database neophytes less perfectionistic and efficiency-obsessed than I).
3) After you've read up on database theory, you've got to spend a fair amount of time planning out your database's organization and structure before you start creating it. Be sure to constantly save backups and ALWAYS thoroughly test your database before you start entering in reams of data! If you don't, you can waste a lot of time having to redo your work. I hope these pages give some suggestions.
4) You've got to perform periodic data cleaning. This is particularly important if you import records from a word processing program into Access, as the validation features aren't automatically applied and neither are automatically-added values entered. Fortunately you can find many consistent errors in your data with queries and mass update them as needed. And use the Replace feature in Word with wildcards and Excel as an import go-between to take advantage of its Text to Column command (described on the next page).
5) Some people have mentioned potential difficulties upgrading from one version of a RDBMS to another (e.g. from Access 97 to Access 2000 to Access 2002). Several people on the history-digitization listserv have mentioned the dangers of relying upon proprietary software for long-term storage. In general, I feel more comfortable with an inexpensive, brand-name product like Microsoft than with a specialized niche product created and maintained by a few scholars whose future is uncertain at best or with an open-source product that requires you to be a computer genius just to use it - perhaps if I was an institution with significant funding, a several-century horizon and held the copyright on the materials I might think differently. I have had no problems converting my Access 97 database directly to Access 2002 format - all of the code still works fine, even if there are more efficient ways of writing some of the code in 2002. If some revolutionary program does appear in the future, you can convert your database information to standard ASCII or txt tab-delimited documents (Access 2002 now allows XML exporting as well) and then convert them to any conceivable format/program of the future - any new software will be backwards-compatible from these formats. I was able to do this quite easily converting my EndNote secondary sources into Access (with a few minor glitches due to differences in the structure of the two databases). More likely than relying on a generic format, you will probably be able to convert data from Microsoft Access to any other format directly; if Microsoft does lose its dominance, you can be sure there will be many companies offering conversion utilities for the thousands and thousands of individuals and small businesses that use Access.
While the learning curve may be somewhat steep (other simpler, less-powerful RDBMSs such as FileMaker Pro are easier to use; I know I had plenty of frustration trying to reconcile what I wanted Access to do with what it could do, but then I always know what it should be able to do, even if it can't, and my demands are rather extreme), the labor savings in the long-run are undeniable. Imagine how much time you'll no longer waste looking for that one anecdote that you can't locate, or the time you spend making and managing dispersed meta-notes, "second-order" notes on what your notes say (the Summary field handles this nicely). You will take more-valuable notes: much more information will be recorded more quickly, more efficiently and more accurately than before. You will always have the required information available for you after you've come back from the archives no matter where you are (with a laptop). You will be able to explore your notes in ways that were practically impossible (or at least time-prohibitively so) with a traditional note management system. Multiply this by the number of searches you normally perform and by the number of years you plan on doing history, and the savings are staggering, especially if you're using OCR software to speed up data entry.
Having extolled the virtues of a note-taking database, click here to see a detailed description of each field and some of the design considerations I've spent many months pondering. I probably spent more time than one needs developing the database, and you, dear reader, have the advantage in that I've already spelled out what I think are the main issues at this site - but don't be discouraged, as most of the time was actually spent creating a much more complicated, quantitative siege database, which has lots of fields, forms and subforms. You can also look at the Personalities form I've created, although this is less finished than the Notes form.
Note: I have been using EndNote for years, but having created this Notes database in Access, I find myself wishing I knew how to do things in EndNote that I know how to do in Access (my latest brainstorm is to print off bibliographic info labels to put on photocopied book chapters and articles instead of writing them all out by hand - especially handy for chapters in edited works). I have just finished converting my EndNote data over into a new Secondary database that combines bibliographic fields with many of the note-taking fields in my Notes database. This allows me to do detailed searches on topics in both secondary and primary sources, while streamlining the secondary form by eliminating many of the fields irrelevant to secondary sources. I'll also be able to integrate the Secondary and Primary databases together, using the keyword fields, etc.
I also use a dedicated statistical application, Minitab, for dedicated quantitative analysis. One advantage that Access' rudimentary statistical functions does have, however, is that you can re-run the same stat query over as the data changes, rather than having to re-issue the commands in Minitab (although I suppose you could write a script in Minitab that would automate your standard analyses).
| Gateway (home) |
Top | Database
description (next) |
Personalities | Sample Queries |
Last edited 01/10/2003